 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContinual Learning Using Task Conditional Neural Networks
May 08, 2020
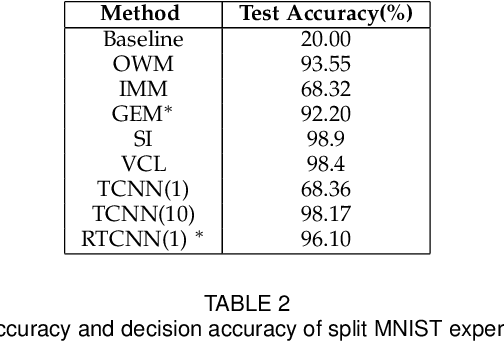
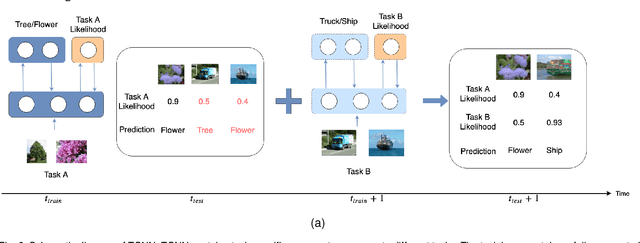
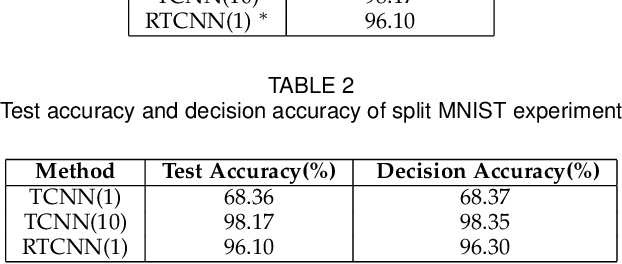
Conventional deep learning models have limited capacity in learning multiple tasks sequentially. The issue of forgetting the previously learned tasks in continual learning is known as catastrophic forgetting or interference. When the input data or the goal of learning change, a continual model will learn and adapt to the new status. However, the model will not remember or recognise any revisits to the previous states. This causes performance reduction and re-training curves in dealing with periodic or irregularly reoccurring changes in the data or goals. The changes in goals or data are referred to as new tasks in a continual learning model. Most of the continual learning methods have a task-known setup in which the task identities are known in advance to the learning model. We propose Task Conditional Neural Networks (TCNN) that does not require to known the reoccurring tasks in advance. We evaluate our model on standard datasets using MNIST and CIFAR10, and also a real-world dataset that we have collected in a remote healthcare monitoring study (i.e. TIHM dataset). The proposed model outperforms the state-of-the-art solutions in continual learning and adapting to new tasks that are not defined in advance.
Continual Learning Using Bayesian Neural Networks
Oct 09, 2019

Continual learning models allow to learn and adapt to new changes and tasks over time. However, in continual and sequential learning scenarios in which the models are trained using different data with various distributions, neural networks tend to forget the previously learned knowledge. This phenomenon is often referred to as catastrophic forgetting. The catastrophic forgetting is an inevitable problem in continual learning models for dynamic environments. To address this issue, we propose a method, called Continual Bayesian Learning Networks (CBLN), which enables the networks to allocate additional resources to adapt to new tasks without forgetting the previously learned tasks. Using a Bayesian Neural Network, CBLN maintains a mixture of Gaussian posterior distributions that are associated with different tasks. The proposed method tries to optimise the number of resources that are needed to learn each task and avoids an exponential increase in the number of resources that are involved in learning multiple tasks. The proposed method does not need to access the past training data and can choose suitable weights to classify the data points during the test time automatically based on an uncertainty criterion. We have evaluated our method on the MNIST and UCR time-series datasets. The evaluation results show that our method can address the catastrophic forgetting problem at a promising rate compared to the state-of-the-art models.
Continual Learning in Deep Neural Network by Using a Kalman Optimiser
May 24, 2019
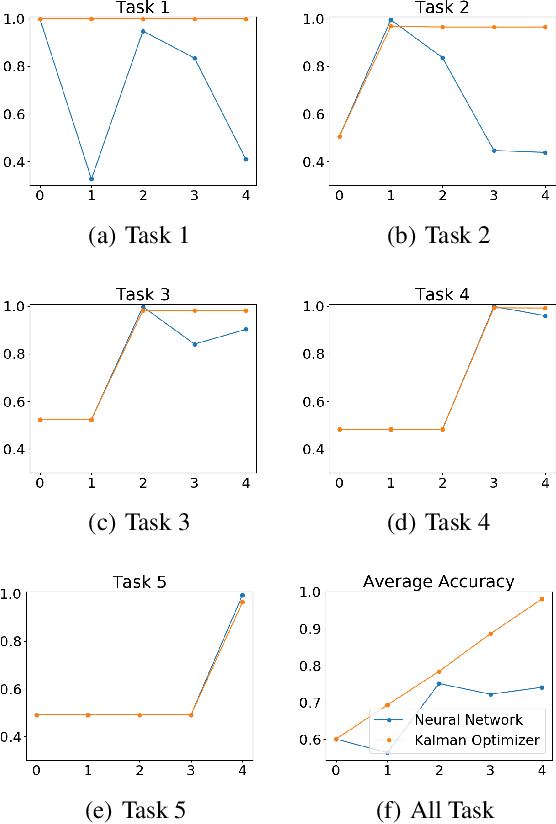
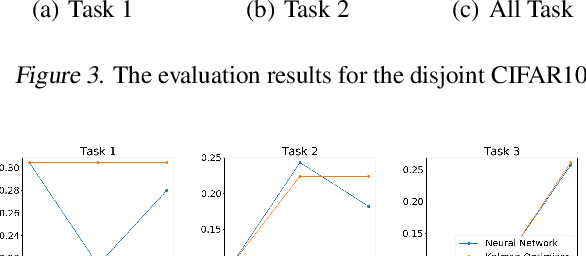
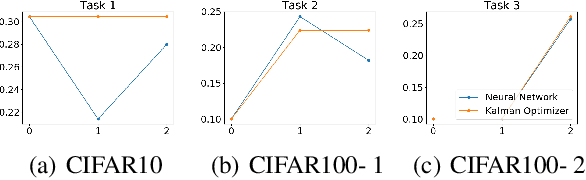
Learning and adapting to new distributions or learning new tasks sequentially without forgetting the previously learned knowledge is a challenging phenomenon in continual learning models. Most of the conventional deep learning models are not capable of learning new tasks sequentially in one model without forgetting the previously learned ones. We address this issue by using a Kalman Optimiser. The Kalman Optimiser divides the neural network into two parts: the long-term and short-term memory units. The long-term memory unit is used to remember the learned tasks and the short-term memory unit is to adapt to the new task. We have evaluated our method on MNIST, CIFAR10, CIFAR100 datasets and compare our results with state-of-the-art baseline models. The results show that our approach enables the model to continually learn and adapt to the new changes without forgetting the previously learned tasks.
Kalman Filter Modifier for Neural Networks in Non-stationary Environments
Nov 06, 2018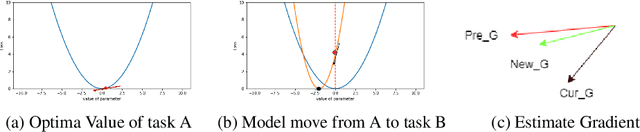
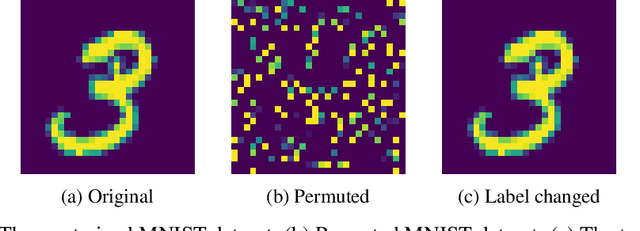
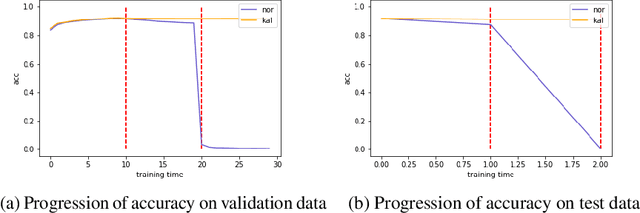
Learning in a non-stationary environment is an inevitable problem when applying machine learning algorithm to real world environment. Learning new tasks without forgetting the previous knowledge is a challenge issue in machine learning. We propose a Kalman Filter based modifier to maintain the performance of Neural Network models under non-stationary environments. The result shows that our proposed model can preserve the key information and adapts better to the changes. The accuracy of proposed model decreases by 0.4% in our experiments, while the accuracy of conventional model decreases by 90% in the drifts environment.
Segment Parameter Labelling in MCMC Mean-Shift Change Detection
Oct 26, 2017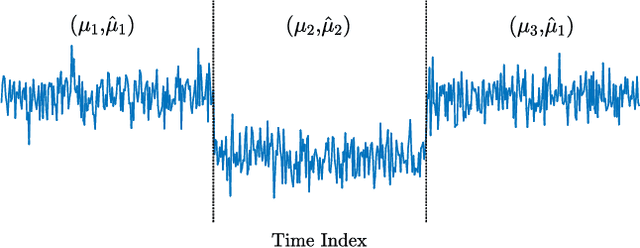
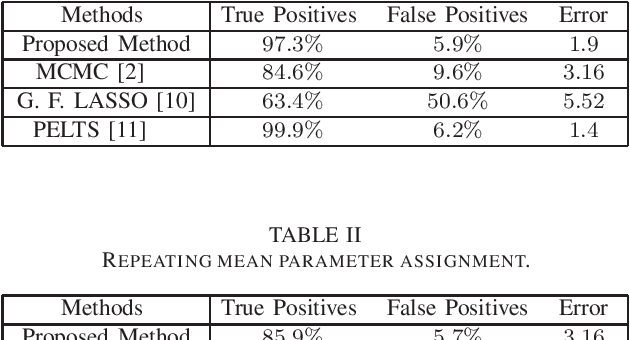
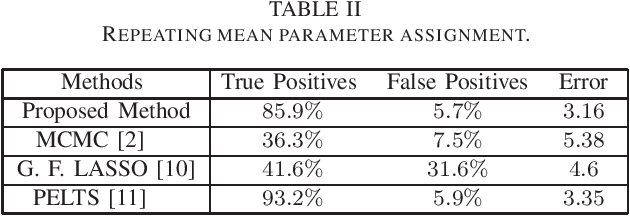
This work addresses the problem of segmentation in time series data with respect to a statistical parameter of interest in Bayesian models. It is common to assume that the parameters are distinct within each segment. As such, many Bayesian change point detection models do not exploit the segment parameter patterns, which can improve performance. This work proposes a Bayesian mean-shift change point detection algorithm that makes use of repetition in segment parameters, by introducing segment class labels that utilise a Dirichlet process prior. The performance of the proposed approach was assessed on both synthetic and real world data, highlighting the enhanced performance when using parameter labelling.