 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Weakly Supervised Learning for Road Extraction from Satellite Imagery
Sep 14, 2023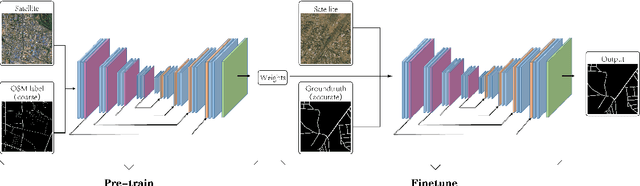
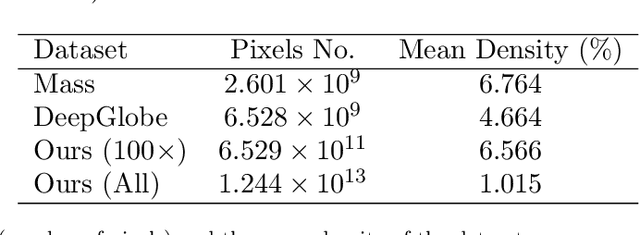
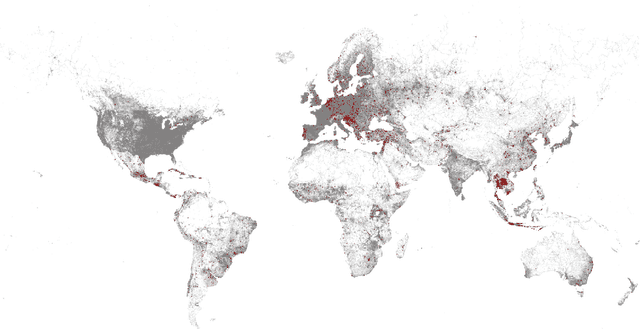

Automatic road extraction from satellite imagery using deep learning is a viable alternative to traditional manual mapping. Therefore it has received considerable attention recently. However, most of the existing methods are supervised and require pixel-level labeling, which is tedious and error-prone. To make matters worse, the earth has a diverse range of terrain, vegetation, and man-made objects. It is well known that models trained in one area generalize poorly to other areas. Various shooting conditions such as light and angel, as well as different image processing techniques further complicate the issue. It is impractical to develop training data to cover all image styles. This paper proposes to leverage OpenStreetMap road data as weak labels and large scale satellite imagery to pre-train semantic segmentation models. Our extensive experimental results show that the prediction accuracy increases with the amount of the weakly labeled data, as well as the road density in the areas chosen for training. Using as much as 100 times more data than the widely used DeepGlobe road dataset, our model with the D-LinkNet architecture and the ResNet-50 backbone exceeds the top performer of the current DeepGlobe leaderboard. Furthermore, due to large-scale pre-training, our model generalizes much better than those trained with only the curated datasets, implying great application potential.