 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEAA-Net: Rethinking the Autoencoder Architecture with Intra-class Features for Medical Image Segmentation
Aug 19, 2022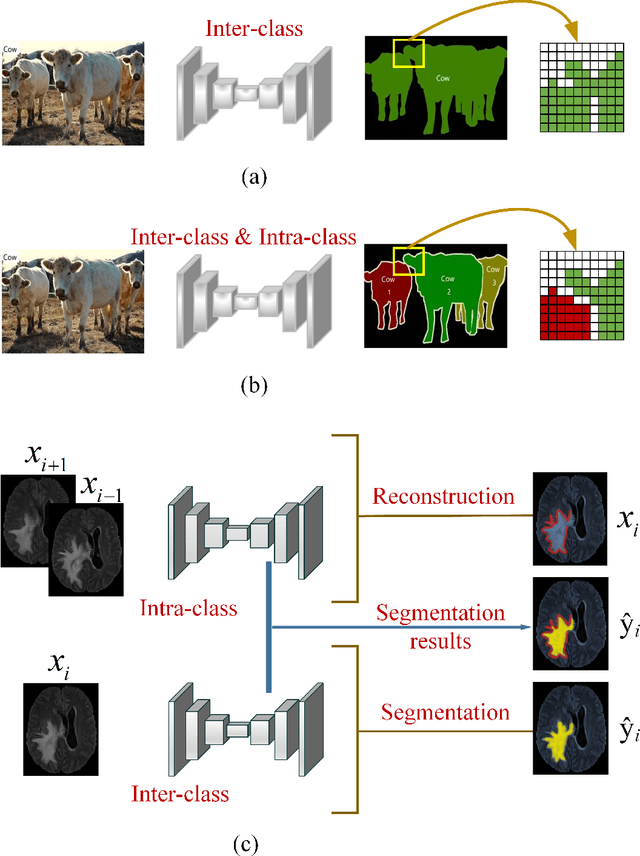
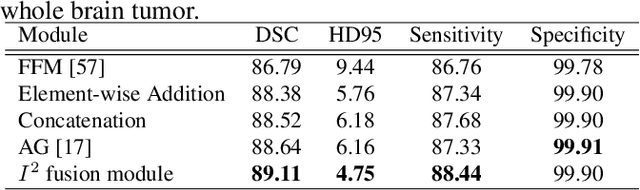
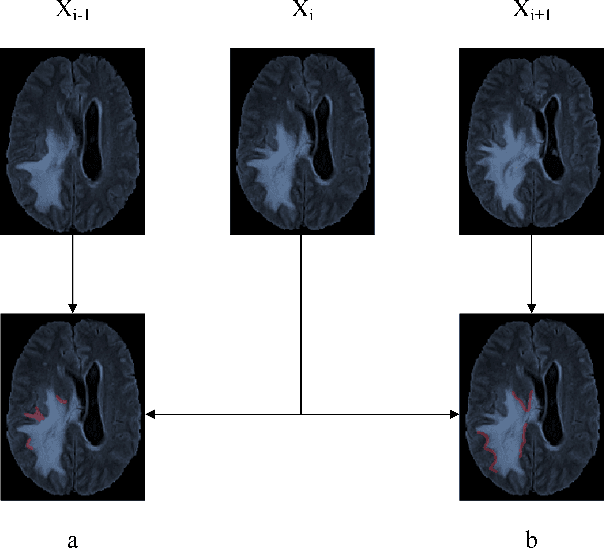
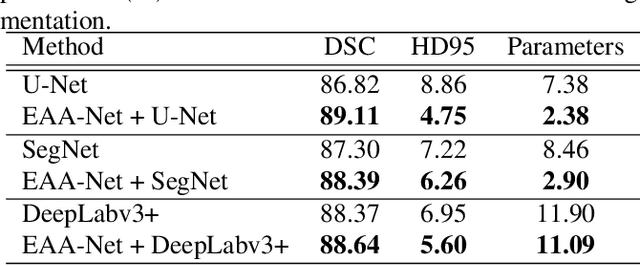
Automatic image segmentation technology is critical to the visual analysis. The autoencoder architecture has satisfying performance in various image segmentation tasks. However, autoencoders based on convolutional neural networks (CNN) seem to encounter a bottleneck in improving the accuracy of semantic segmentation. Increasing the inter-class distance between foreground and background is an inherent characteristic of the segmentation network. However, segmentation networks pay too much attention to the main visual difference between foreground and background, and ignores the detailed edge information, which leads to a reduction in the accuracy of edge segmentation. In this paper, we propose a light-weight end-to-end segmentation framework based on multi-task learning, termed Edge Attention autoencoder Network (EAA-Net), to improve edge segmentation ability. Our approach not only utilizes the segmentation network to obtain inter-class features, but also applies the reconstruction network to extract intra-class features among the foregrounds. We further design a intra-class and inter-class features fusion module -- I2 fusion module. The I2 fusion module is used to merge intra-class and inter-class features, and use a soft attention mechanism to remove invalid background information. Experimental results show that our method performs well in medical image segmentation tasks. EAA-Net is easy to implement and has small calculation cost.
TranSiam: Fusing Multimodal Visual Features Using Transformer for Medical Image Segmentation
Apr 26, 2022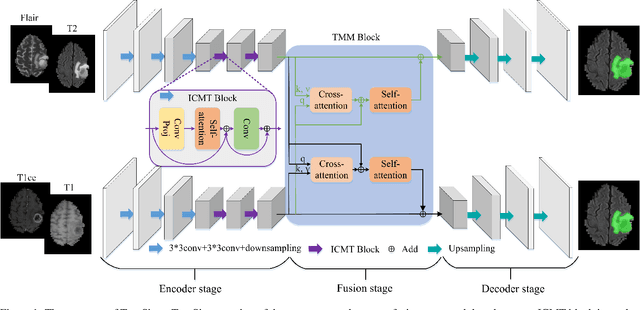
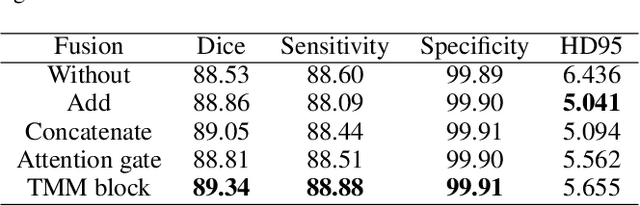
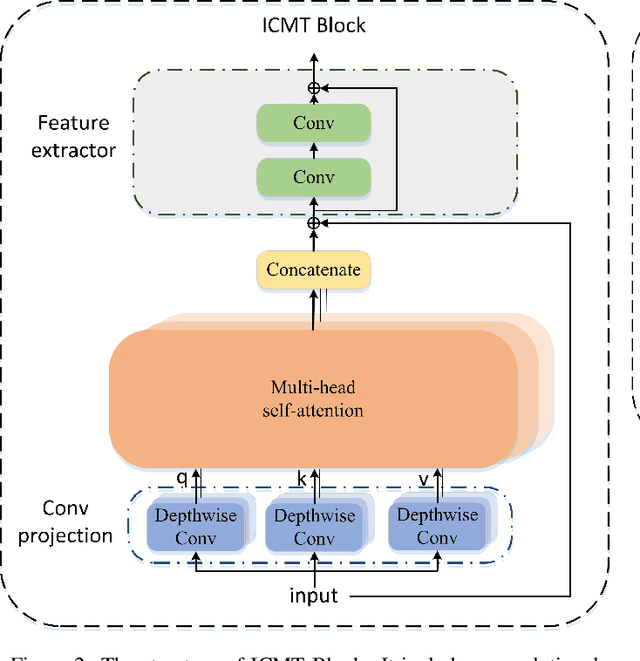
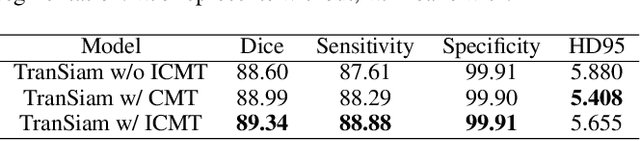
Automatic segmentation of medical images based on multi-modality is an important topic for disease diagnosis. Although the convolutional neural network (CNN) has been proven to have excellent performance in image segmentation tasks, it is difficult to obtain global information. The lack of global information will seriously affect the accuracy of the segmentation results of the lesion area. In addition, there are visual representation differences between multimodal data of the same patient. These differences will affect the results of the automatic segmentation methods. To solve these problems, we propose a segmentation method suitable for multimodal medical images that can capture global information, named TranSiam. TranSiam is a 2D dual path network that extracts features of different modalities. In each path, we utilize convolution to extract detailed information in low level stage, and design a ICMT block to extract global information in high level stage. ICMT block embeds convolution in the transformer, which can extract global information while retaining spatial and detailed information. Furthermore, we design a novel fusion mechanism based on cross attention and selfattention, called TMM block, which can effectively fuse features between different modalities. On the BraTS 2019 and BraTS 2020 multimodal datasets, we have a significant improvement in accuracy over other popular methods.