 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Strategy Representation for Imitation Learning in Multi-Agent Games
Sep 28, 2024The offline datasets for imitation learning (IL) in multi-agent games typically contain player trajectories exhibiting diverse strategies, which necessitate measures to prevent learning algorithms from acquiring undesirable behaviors. Learning representations for these trajectories is an effective approach to depicting the strategies employed by each demonstrator. However, existing learning strategies often require player identification or rely on strong assumptions, which are not appropriate for multi-agent games. Therefore, in this paper, we introduce the Strategy Representation for Imitation Learning (STRIL) framework, which (1) effectively learns strategy representations in multi-agent games, (2) estimates proposed indicators based on these representations, and (3) filters out sub-optimal data using the indicators. STRIL is a plug-in method that can be integrated into existing IL algorithms. We demonstrate the effectiveness of STRIL across competitive multi-agent scenarios, including Two-player Pong, Limit Texas Hold'em, and Connect Four. Our approach successfully acquires strategy representations and indicators, thereby identifying dominant trajectories and significantly enhancing existing IL performance across these environments.
ELA: Exploited Level Augmentation for Offline Learning in Zero-Sum Games
Feb 28, 2024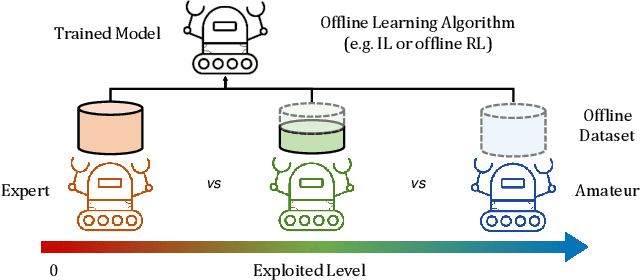


Offline learning has become widely used due to its ability to derive effective policies from offline datasets gathered by expert demonstrators without interacting with the environment directly. Recent research has explored various ways to enhance offline learning efficiency by considering the characteristics (e.g., expertise level or multiple demonstrators) of the dataset. However, a different approach is necessary in the context of zero-sum games, where outcomes vary significantly based on the strategy of the opponent. In this study, we introduce a novel approach that uses unsupervised learning techniques to estimate the exploited level of each trajectory from the offline dataset of zero-sum games made by diverse demonstrators. Subsequently, we incorporate the estimated exploited level into the offline learning to maximize the influence of the dominant strategy. Our method enables interpretable exploited level estimation in multiple zero-sum games and effectively identifies dominant strategy data. Also, our exploited level augmented offline learning significantly enhances the original offline learning algorithms including imitation learning and offline reinforcement learning for zero-sum games.