 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Inference via Generative Models: Flow Matching and Causal Inference
Mar 09, 2026Generative AI has achieved remarkable empirical success, but from the perspective of statistics it often remains opaque: its predictions may be accurate, yet the underlying mechanism is difficult to interpret, analyze, and trust. This book reinterprets generative AI in the language of statistics, using flow matching as a central example. The key idea is that generative models should be understood not merely as devices for producing plausible data, but as methods for the nonparametric learning of high-dimensional probability distributions. From this viewpoint, missing-data imputation becomes principled sampling from learned conditional distributions, counterfactual analysis becomes the estimation of intervention distributions, and distributional dynamics become statistically analyzable objects. Mathematically, flow matching represents distributional deformation through the continuity equation and a time-dependent velocity field, thereby extending score matching from the learning of static score fields to the learning of transport paths themselves. Building on this foundation, the book develops a statistical framework in which generative models are used to estimate nuisance components while inferential validity is maintained through orthogonalization and cross-fitting in the spirit of double/debiased machine learning. Applications to survival analysis, censoring, missingness, and causal inference show how generative models can be integrated into statistical inference for structured high-dimensional problems.
Implicit geometric regularization in flow matching via density weighted Stein operators
Dec 30, 2025Flow Matching (FM) has emerged as a powerful paradigm for continuous normalizing flows, yet standard FM implicitly performs an unweighted $L^2$ regression over the entire ambient space. In high dimensions, this leads to a fundamental inefficiency: the vast majority of the integration domain consists of low-density ``void'' regions where the target velocity fields are often chaotic or ill-defined. In this paper, we propose {$γ$-Flow Matching ($γ$-FM)}, a density-weighted variant that aligns the regression geometry with the underlying probability flow. While density weighting is desirable, naive implementations would require evaluating the intractable target density. We circumvent this by introducing a Dynamic Density-Weighting strategy that estimates the \emph{target} density directly from training particles. This approach allows us to dynamically downweight the regression loss in void regions without compromising the simulation-free nature of FM. Theoretically, we establish that $γ$-FM minimizes the transport cost on a statistical manifold endowed with the $γ$-Stein metric. Spectral analysis further suggests that this geometry induces an implicit Sobolev regularization, effectively damping high-frequency oscillations in void regions. Empirically, $γ$-FM significantly improves vector field smoothness and sampling efficiency on high-dimensional latent datasets, while demonstrating intrinsic robustness to outliers.
Robust inference using density-powered Stein operators
Nov 06, 2025
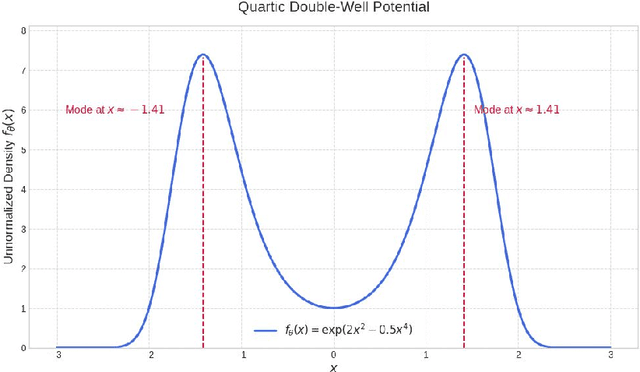
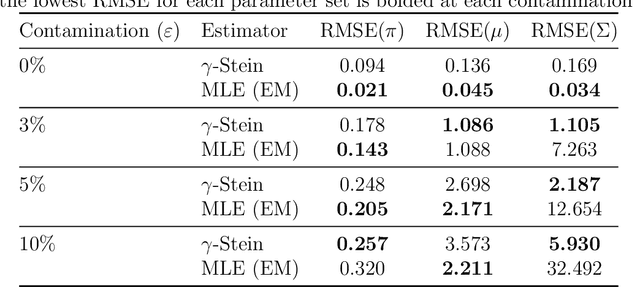

We introduce a density-power weighted variant for the Stein operator, called the $γ$-Stein operator. This is a novel class of operators derived from the $γ$-divergence, designed to build robust inference methods for unnormalized probability models. The operator's construction (weighting by the model density raised to a positive power $γ$ inherently down-weights the influence of outliers, providing a principled mechanism for robustness. Applying this operator yields a robust generalization of score matching that retains the crucial property of being independent of the model's normalizing constant. We extend this framework to develop two key applications: the $γ$-kernelized Stein discrepancy for robust goodness-of-fit testing, and $γ$-Stein variational gradient descent for robust Bayesian posterior approximation. Empirical results on contaminated Gaussian and quartic potential models show our methods significantly outperform standard baselines in both robustness and statistical efficiency.
A Generalized Mean Approach for Distributed-PCA
Oct 01, 2024

Principal component analysis (PCA) is a widely used technique for dimension reduction. As datasets continue to grow in size, distributed-PCA (DPCA) has become an active research area. A key challenge in DPCA lies in efficiently aggregating results across multiple machines or computing nodes due to computational overhead. Fan et al. (2019) introduced a pioneering DPCA method to estimate the leading rank-$r$ eigenspace, aggregating local rank-$r$ projection matrices by averaging. However, their method does not utilize eigenvalue information. In this article, we propose a novel DPCA method that incorporates eigenvalue information to aggregate local results via the matrix $\beta$-mean, which we call $\beta$-DPCA. The matrix $\beta$-mean offers a flexible and robust aggregation method through the adjustable choice of $\beta$ values. Notably, for $\beta=1$, it corresponds to the arithmetic mean; for $\beta=-1$, the harmonic mean; and as $\beta \to 0$, the geometric mean. Moreover, the matrix $\beta$-mean is shown to associate with the matrix $\beta$-divergence, a subclass of the Bregman matrix divergence, to support the robustness of $\beta$-DPCA. We also study the stability of eigenvector ordering under eigenvalue perturbation for $\beta$-DPCA. The performance of our proposal is evaluated through numerical studies.
Active Learning by Query by Committee with Robust Divergences
Nov 18, 2022Active learning is a widely used methodology for various problems with high measurement costs. In active learning, the next object to be measured is selected by an acquisition function, and measurements are performed sequentially. The query by committee is a well-known acquisition function. In conventional methods, committee disagreement is quantified by the Kullback--Leibler divergence. In this paper, the measure of disagreement is defined by the Bregman divergence, which includes the Kullback--Leibler divergence as an instance, and the dual $\gamma$-power divergence. As a particular class of the Bregman divergence, the $\beta$-divergence is considered. By deriving the influence function, we show that the proposed method using $\beta$-divergence and dual $\gamma$-power divergence are more robust than the conventional method in which the measure of disagreement is defined by the Kullback--Leibler divergence. Experimental results show that the proposed method performs as well as or better than the conventional method.
Minimum information divergence of Q-functions for dynamic treatment resumes
Nov 16, 2022This paper aims at presenting a new application of information geometry to reinforcement learning focusing on dynamic treatment resumes. In a standard framework of reinforcement learning, a Q-function is defined as the conditional expectation of a reward given a state and an action for a single-stage situation. We introduce an equivalence relation, called the policy equivalence, in the space of all the Q-functions. A class of information divergence is defined in the Q-function space for every stage. The main objective is to propose an estimator of the optimal policy function by a method of minimum information divergence based on a dataset of trajectories. In particular, we discuss the $\gamma$-power divergence that is shown to have an advantageous property such that the $\gamma$-power divergence between policy-equivalent Q-functions vanishes. This property essentially works to seek the optimal policy, which is discussed in a framework of a semiparametric model for the Q-function. The specific choices of power index $\gamma$ give interesting relationships of the value function, and the geometric and harmonic means of the Q-function. A numerical experiment demonstrates the performance of the minimum $\gamma$-power divergence method in the context of dynamic treatment regimes.