 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning with Posterior Sampling for Revenue Management under Time-varying Demand
May 08, 2024



This paper discusses the revenue management (RM) problem to maximize revenue by pricing items or services. One challenge in this problem is that the demand distribution is unknown and varies over time in real applications such as airline and retail industries. In particular, the time-varying demand has not been well studied under scenarios of unknown demand due to the difficulty of jointly managing the remaining inventory and estimating the demand. To tackle this challenge, we first introduce an episodic generalization of the RM problem motivated by typical application scenarios. We then propose a computationally efficient algorithm based on posterior sampling, which effectively optimizes prices by solving linear programming. We derive a Bayesian regret upper bound of this algorithm for general models where demand parameters can be correlated between time periods, while also deriving a regret lower bound for generic algorithms. Our empirical study shows that the proposed algorithm performs better than other benchmark algorithms and comparably to the optimal policy in hindsight. We also propose a heuristic modification of the proposed algorithm, which further efficiently learns the pricing policy in the experiments.
An Autonomous Negotiating Agent Framework with Reinforcement Learning Based Strategies and Adaptive Strategy Switching Mechanism
Feb 09, 2021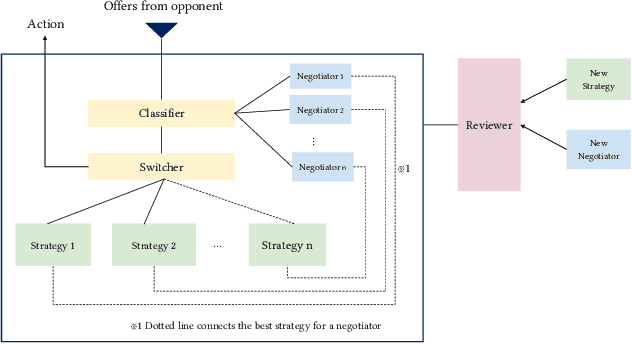


Despite abundant negotiation strategies in literature, the complexity of automated negotiation forbids a single strategy from being dominant against all others in different negotiation scenarios. To overcome this, one approach is to use mixture of experts, but at the same time, one problem of this method is the selection of experts, as this approach is limited by the competency of the experts selected. Another problem with most negotiation strategies is their incapability of adapting to dynamic variation of the opponent's behaviour within a single negotiation session resulting in poor performance. This work focuses on both, solving the problem of expert selection and adapting to the opponent's behaviour with our Autonomous Negotiating Agent Framework. This framework allows real-time classification of opponent's behaviour and provides a mechanism to select, switch or combine strategies within a single negotiation session. Additionally, our framework has a reviewer component which enables self-enhancement capability by deciding to include new strategies or replace old ones with better strategies periodically. We demonstrate an instance of our framework by implementing maximum entropy reinforcement learning based strategies with a deep learning based opponent classifier. Finally, we evaluate the performance of our agent against state-of-the-art negotiators under varied negotiation scenarios.