 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeuristics for Combinatorial Optimization via Value-based Reinforcement Learning: A Unified Framework and Analysis
Dec 09, 2025Since the 1990s, considerable empirical work has been carried out to train statistical models, such as neural networks (NNs), as learned heuristics for combinatorial optimization (CO) problems. When successful, such an approach eliminates the need for experts to design heuristics per problem type. Due to their structure, many hard CO problems are amenable to treatment through reinforcement learning (RL). Indeed, we find a wealth of literature training NNs using value-based, policy gradient, or actor-critic approaches, with promising results, both in terms of empirical optimality gaps and inference runtimes. Nevertheless, there has been a paucity of theoretical work undergirding the use of RL for CO problems. To this end, we introduce a unified framework to model CO problems through Markov decision processes (MDPs) and solve them using RL techniques. We provide easy-to-test assumptions under which CO problems can be formulated as equivalent undiscounted MDPs that provide optimal solutions to the original CO problems. Moreover, we establish conditions under which value-based RL techniques converge to approximate solutions of the CO problem with a guarantee on the associated optimality gap. Our convergence analysis provides: (1) a sufficient rate of increase in batch size and projected gradient descent steps at each RL iteration; (2) the resulting optimality gap in terms of problem parameters and targeted RL accuracy; and (3) the importance of a choice of state-space embedding. Together, our analysis illuminates the success (and limitations) of the celebrated deep Q-learning algorithm in this problem context.
A conditional gradient homotopy method with applications to Semidefinite Programming
Jul 07, 2022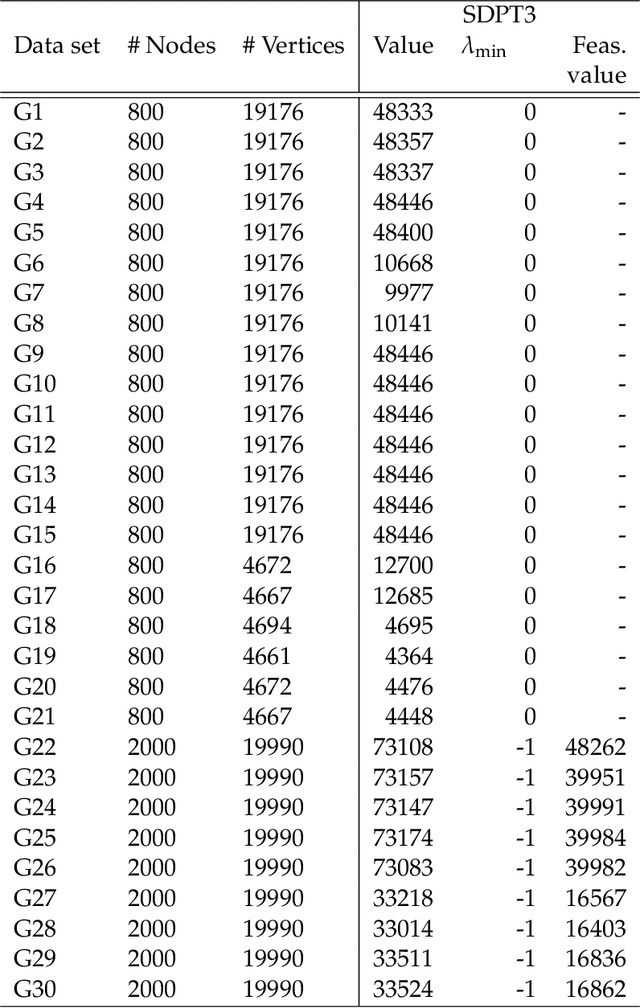
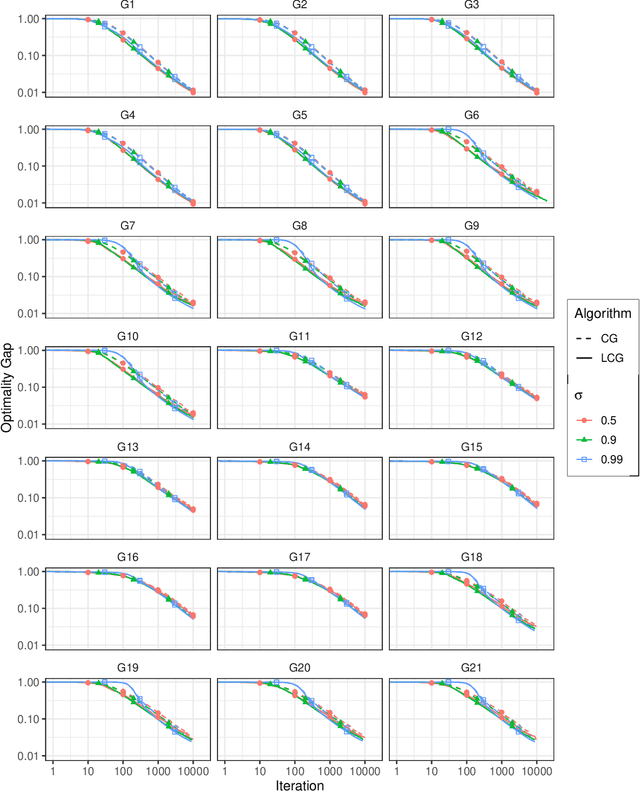
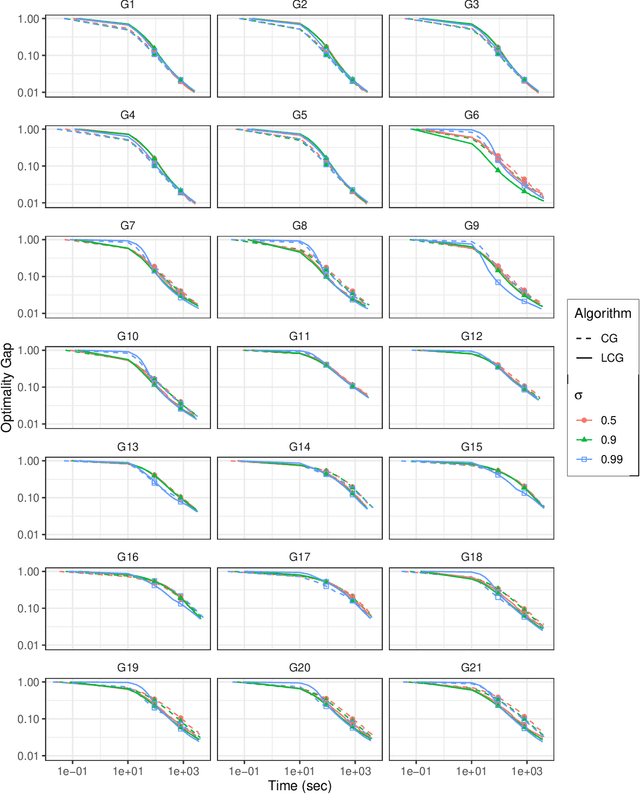
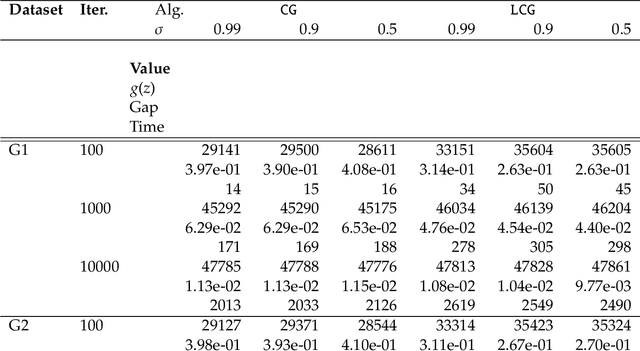
We propose a new homotopy-based conditional gradient method for solving convex optimization problems with a large number of simple conic constraints. Instances of this template naturally appear in semidefinite programming problems arising as convex relaxations of combinatorial optimization problems. Our method is a double-loop algorithm in which the conic constraint is treated via a self-concordant barrier, and the inner loop employs a conditional gradient algorithm to approximate the analytic central path, while the outer loop updates the accuracy imposed on the temporal solution and the homotopy parameter. Our theoretical iteration complexity is competitive when confronted to state-of-the-art SDP solvers, with the decisive advantage of cheap projection-free subroutines. Preliminary numerical experiments are provided for illustrating the practical performance of the method.
First-Order Methods for Convex Optimization
Jan 06, 2021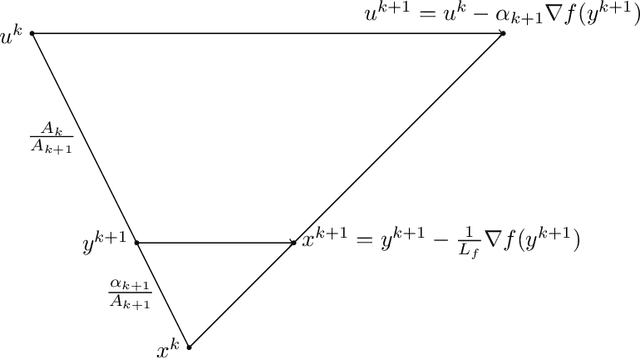
First-order methods for solving convex optimization problems have been at the forefront of mathematical optimization in the last 20 years. The rapid development of this important class of algorithms is motivated by the success stories reported in various applications, including most importantly machine learning, signal processing, imaging and control theory. First-order methods have the potential to provide low accuracy solutions at low computational complexity which makes them an attractive set of tools in large-scale optimization problems. In this survey we cover a number of key developments in gradient-based optimization methods. This includes non-Euclidean extensions of the classical proximal gradient method, and its accelerated versions. Additionally we survey recent developments within the class of projection-free methods, and proximal versions of primal-dual schemes. We give complete proofs for various key results, and highlight the unifying aspects of several optimization algorithms.
Self-concordant analysis of Frank-Wolfe algorithms
Feb 20, 2020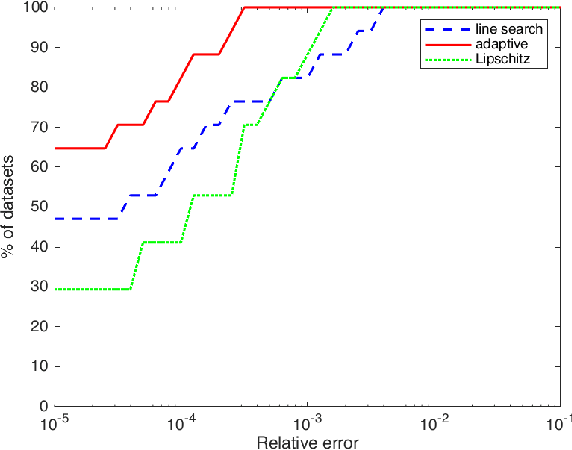
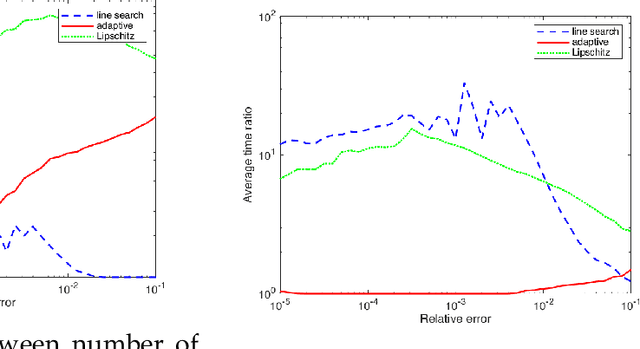
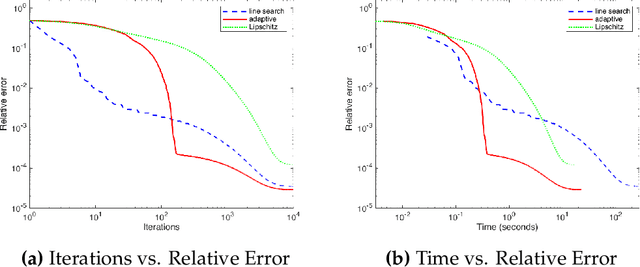
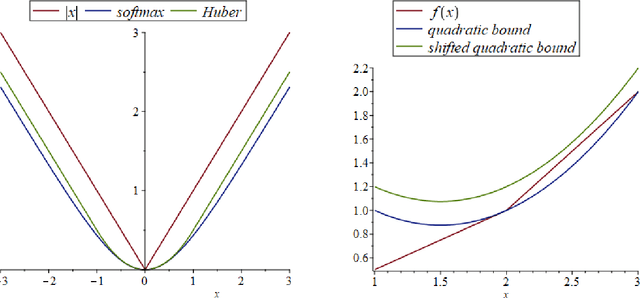
Projection-free optimization via different variants of the Frank-Wolfe (FW) method has become one of the cornerstones in optimization for machine learning since in many cases the linear minimization oracle is much cheaper to implement than projections and some sparsity needs to be preserved. In a number of applications, e.g. Poisson inverse problems or quantum state tomography, the loss is given by a self-concordant (SC) function having unbounded curvature, implying absence of theoretical guarantees for the existing FW methods. We use the theory of SC functions to provide a new adaptive step size for FW methods and prove global convergence rate O(1/k), k being the iteration counter. If the problem can be represented by a local linear minimization oracle, we are the first to propose a FW method with linear convergence rate without assuming neither strong convexity nor a Lipschitz continuous gradient.