 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAoECR: AI-ization of Elderly Care Robot
Feb 27, 2025Autonomous interaction is crucial for the effective use of elderly care robots. However, developing universal AI architectures is extremely challenging due to the diversity in robot configurations and a lack of dataset. We proposed a universal architecture for the AI-ization of elderly care robots, called AoECR. Specifically, based on a nursing bed, we developed a patient-nurse interaction dataset tailored for elderly care scenarios and fine-tuned a large language model to enable it to perform nursing manipulations. Additionally, the inference process included a self-check chain to ensure the security of control commands. An expert optimization process further enhanced the humanization and personalization of the interactive responses. The physical experiment demonstrated that the AoECR exhibited zero-shot generalization capabilities across diverse scenarios, understood patients' instructions, implemented secure control commands, and delivered humanized and personalized interactive responses. In general, our research provides a valuable dataset reference and AI-ization solutions for elderly care robots.
A Single Multi-Task Deep Neural Network with a Multi-Scale Feature Aggregation Mechanism for Manipulation Relationship Reasoning in Robotic Grasping
May 23, 2023



Grasping specific objects in complex and irregularly stacked scenes is still challenging for robotics. Because the robot is not only required to identify the object's grasping posture but also needs to reason the manipulation relationship between the objects. In this paper, we propose a manipulation relationship reasoning network with a multi-scale feature aggregation (MSFA) mechanism for robot grasping tasks. MSFA aggregates high-level semantic information and low-level spatial information in a cross-scale connection way to improve the generalization ability of the model. Furthermore, to improve the accuracy, we propose to use intersection features with rich location priors for manipulation relationship reasoning. Experiments are validated in VMRD datasets and real environments, respectively. The experimental results demonstrate that our proposed method can accurately predict the manipulation relationship between objects in the scene of multi-object stacking. Compared with previous methods, it significantly improves reasoning speed and accuracy.
Real-World Semantic Grasping Detection
Nov 20, 2021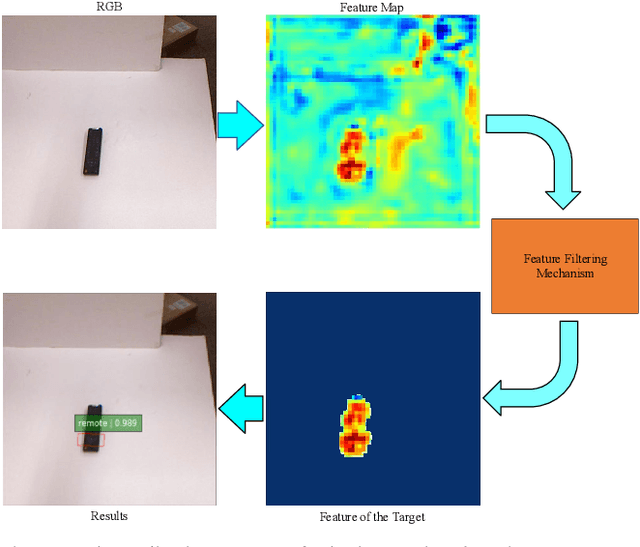
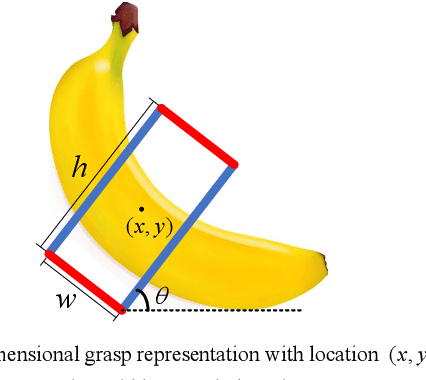
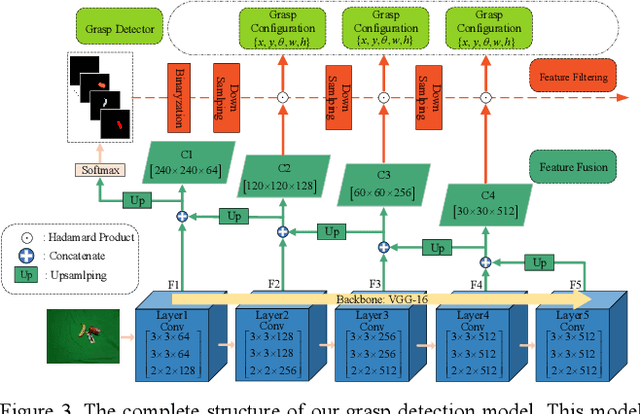

Reducing the scope of grasping detection according to the semantic information of the target is significant to improve the accuracy of the grasping detection model and expand its application. Researchers have been trying to combine these capabilities in an end-to-end network to grasp specific objects in a cluttered scene efficiently. In this paper, we propose an end-to-end semantic grasping detection model, which can accomplish both semantic recognition and grasping detection. And we also design a target feature filtering mechanism, which only maintains the features of a single object according to the semantic information for grasping detection. This method effectively reduces the background features that are weakly correlated to the target object, thus making the features more unique and guaranteeing the accuracy and efficiency of grasping detection. Experimental results show that the proposed method can achieve 98.38% accuracy in Cornell grasping dataset Furthermore, our results on different datasets or evaluation metrics show the domain adaptability of our method over the state-of-the-art.
Mask-GD Segmentation Based Robotic Grasp Detection
Jan 20, 2021
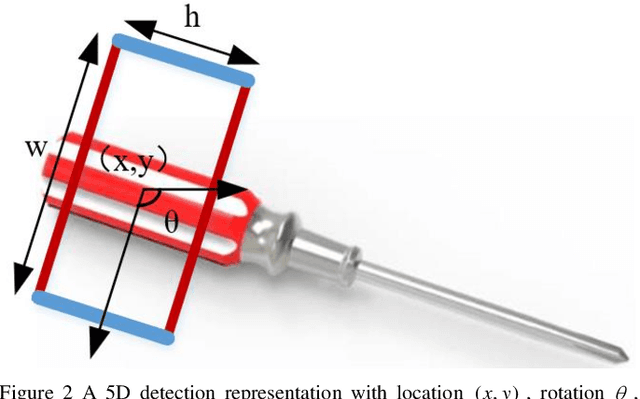
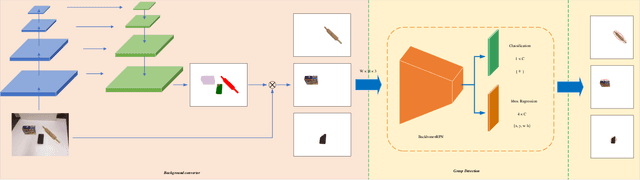
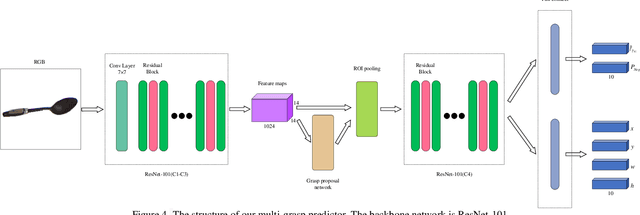
The reliability of grasp detection for target objects in complex scenes is a challenging task and a critical problem that needs to be solved urgently in practical application. At present, the grasp detection location comes from searching the feature space of the whole image. However, the cluttered background information in the image impairs the accuracy of grasping detection. In this paper, a robotic grasp detection algorithm named MASK-GD is proposed, which provides a feasible solution to this problem. MASK is a segmented image that only contains the pixels of the target object. MASK-GD for grasp detection only uses MASK features rather than the features of the entire image in the scene. It has two stages: the first stage is to provide the MASK of the target object as the input image, and the second stage is a grasp detector based on the MASK feature. Experimental results demonstrate that MASK-GD's performance is comparable with state-of-the-art grasp detection algorithms on Cornell Datasets and Jacquard Dataset. In the meantime, MASK-GD performs much better in complex scenes.