 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Train Text Summarization Model with Weak Supervisions
Aug 27, 2024



Currently, machine learning techniques have seen significant success across various applications. Most of these techniques rely on supervision from human-generated labels or a mixture of noisy and imprecise labels from multiple sources. However, for certain complex tasks, even noisy or inexact labels are unavailable due to the intricacy of the objectives. To tackle this issue, we propose a method that breaks down the complex objective into simpler tasks and generates supervision signals for each one. We then integrate these supervision signals into a manageable form, resulting in a straightforward learning procedure. As a case study, we demonstrate a system used for topic-based summarization. This system leverages rich supervision signals to promote both summarization and topic relevance. Remarkably, we can train the model end-to-end without any labels. Experimental results indicate that our approach performs exceptionally well on the CNN and DailyMail datasets.
Accelerated Markov Chain Monte Carlo Using Adaptive Weighting Scheme
Aug 23, 2024
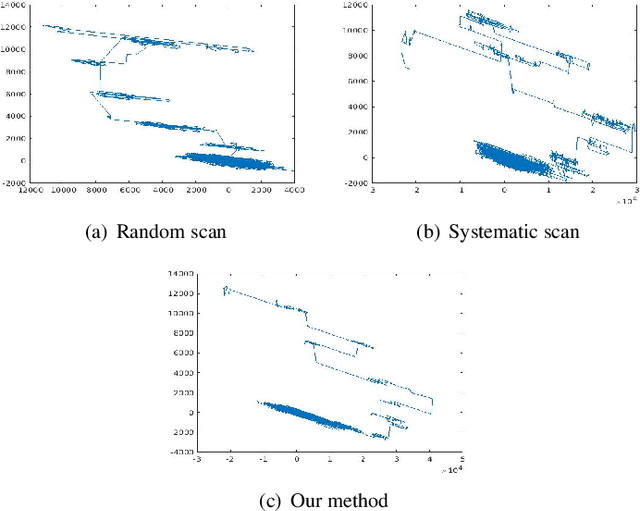


Gibbs sampling is one of the most commonly used Markov Chain Monte Carlo (MCMC) algorithms due to its simplicity and efficiency. It cycles through the latent variables, sampling each one from its distribution conditional on the current values of all the other variables. Conventional Gibbs sampling is based on the systematic scan (with a deterministic order of variables). In contrast, in recent years, Gibbs sampling with random scan has shown its advantage in some scenarios. However, almost all the analyses of Gibbs sampling with the random scan are based on uniform selection of variables. In this paper, we focus on a random scan Gibbs sampling method that selects each latent variable non-uniformly. Firstly, we show that this non-uniform scan Gibbs sampling leaves the target posterior distribution invariant. Then we explore how to determine the selection probability for latent variables. In particular, we construct an objective as a function of the selection probability and solve the constrained optimization problem. We further derive an analytic solution of the selection probability, which can be estimated easily. Our algorithm relies on the simple intuition that choosing the variable updates according to their marginal probabilities enhances the mixing time of the Markov chain. Finally, we validate the effectiveness of the proposed Gibbs sampler by conducting a set of experiments on real-world applications.
AntibodyFlow: Normalizing Flow Model for Designing Antibody Complementarity-Determining Regions
Jun 19, 2024



Therapeutic antibodies have been extensively studied in drug discovery and development in the past decades. Antibodies are specialized protective proteins that bind to antigens in a lock-to-key manner. The binding strength/affinity between an antibody and a specific antigen is heavily determined by the complementarity-determining regions (CDRs) on the antibodies. Existing machine learning methods cast in silico development of CDRs as either sequence or 3D graph (with a single chain) generation tasks and have achieved initial success. However, with CDR loops having specific geometry shapes, learning the 3D geometric structures of CDRs remains a challenge. To address this issue, we propose AntibodyFlow, a 3D flow model to design antibody CDR loops. Specifically, AntibodyFlow first constructs the distance matrix, then predicts amino acids conditioned on the distance matrix. Also, AntibodyFlow conducts constraint learning and constrained generation to ensure valid 3D structures. Experimental results indicate that AntibodyFlow outperforms the best baseline consistently with up to 16.0% relative improvement in validity rate and 24.3% relative reduction in geometric graph level error (root mean square deviation, RMSD).
PGA-SciRE: Harnessing LLM on Data Augmentation for Enhancing Scientific Relation Extraction
May 30, 2024



Relation Extraction (RE) aims at recognizing the relation between pairs of entities mentioned in a text. Advances in LLMs have had a tremendous impact on NLP. In this work, we propose a textual data augmentation framework called PGA for improving the performance of models for RE in the scientific domain. The framework introduces two ways of data augmentation, utilizing a LLM to obtain pseudo-samples with the same sentence meaning but with different representations and forms by paraphrasing the original training set samples. As well as instructing LLM to generate sentences that implicitly contain information about the corresponding labels based on the relation and entity of the original training set samples. These two kinds of pseudo-samples participate in the training of the RE model together with the original dataset, respectively. The PGA framework in the experiment improves the F1 scores of the three mainstream models for RE within the scientific domain. Also, using a LLM to obtain samples can effectively reduce the cost of manually labeling data.