 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Exploring and Improving Robustness of Scene Text Detection Models
Oct 12, 2021

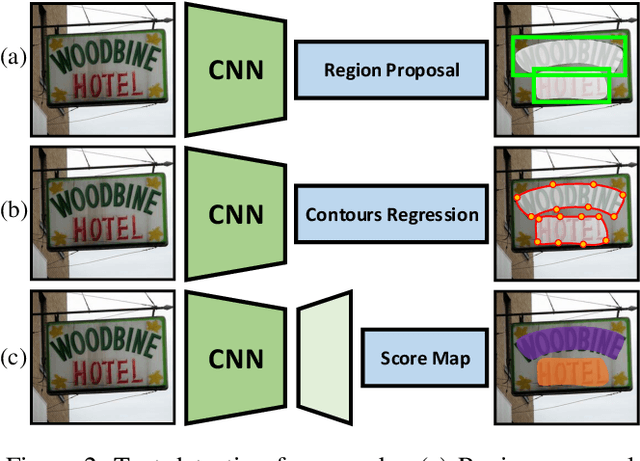
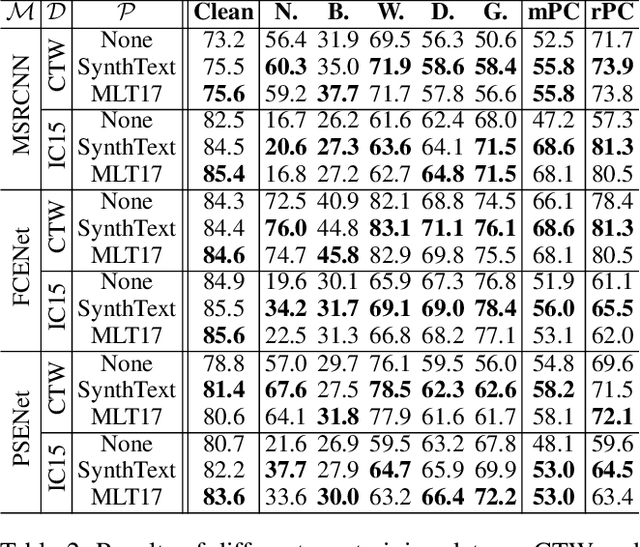
It is crucial to understand the robustness of text detection models with regard to extensive corruptions, since scene text detection techniques have many practical applications. For systematically exploring this problem, we propose two datasets from which to evaluate scene text detection models: ICDAR2015-C (IC15-C) and CTW1500-C (CTW-C). Our study extends the investigation of the performance and robustness of the proposed region proposal, regression and segmentation-based scene text detection frameworks. Furthermore, we perform a robustness analysis of six key components: pre-training data, backbone, feature fusion module, multi-scale predictions, representation of text instances and loss function. Finally, we present a simple yet effective data-based method to destroy the smoothness of text regions by merging background and foreground, which can significantly increase the robustness of different text detection networks. We hope that this study will provide valid data points as well as experience for future research. Benchmark, code and data will be made available at \url{https://github.com/wushilian/robust-scene-text-detection-benchmark}.