 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelating the Neural Representations of Vocalized, Mimed, and Imagined Speech
Feb 26, 2026We investigated the relationship among neural representations of vocalized, mimed, and imagined speech recorded using publicly available stereotactic EEG recordings. Most prior studies have focused on decoding speech responses within each condition separately. Here, instead, we explore how responses across conditions relate by training linear spectrogram reconstruction models for each condition and evaluate their generalization across conditions. We demonstrate that linear decoders trained on one condition generally transfer successfully to others, implying shared speech representations. This commonality was assessed with stimulus-level discriminability by performing a rank-based analysis demonstrating preservation of stimulus-specific structure in both within- and across-conditions. Finally, we compared linear reconstructions to those from a nonlinear neural network. While both exhibited cross-condition transfer, linear models achieve superior stimulus-level discriminability.
Biomimetic Frontend for Differentiable Audio Processing
Sep 13, 2024While models in audio and speech processing are becoming deeper and more end-to-end, they as a consequence need expensive training on large data, and are often brittle. We build on a classical model of human hearing and make it differentiable, so that we can combine traditional explainable biomimetic signal processing approaches with deep-learning frameworks. This allows us to arrive at an expressive and explainable model that is easily trained on modest amounts of data. We apply this model to audio processing tasks, including classification and enhancement. Results show that our differentiable model surpasses black-box approaches in terms of computational efficiency and robustness, even with little training data. We also discuss other potential applications.
Recursive Sparse Point Process Regression with Application to Spectrotemporal Receptive Field Plasticity Analysis
Jul 16, 2015
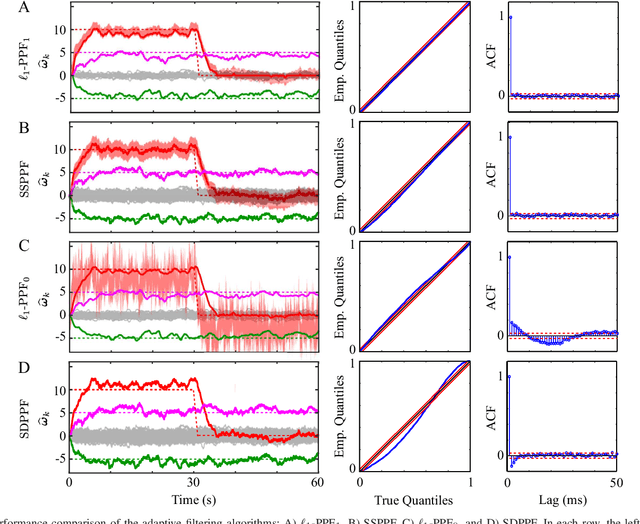

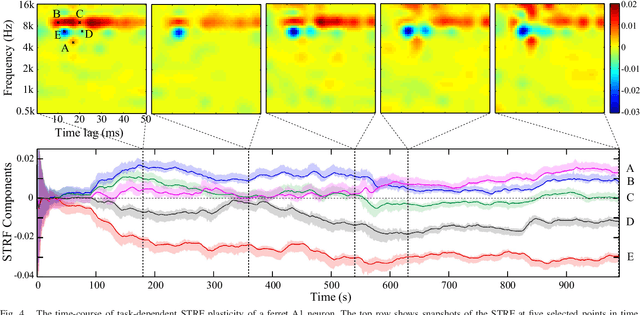
We consider the problem of estimating the sparse time-varying parameter vectors of a point process model in an online fashion, where the observations and inputs respectively consist of binary and continuous time series. We construct a novel objective function by incorporating a forgetting factor mechanism into the point process log-likelihood to enforce adaptivity and employ $\ell_1$-regularization to capture the sparsity. We provide a rigorous analysis of the maximizers of the objective function, which extends the guarantees of compressed sensing to our setting. We construct two recursive filters for online estimation of the parameter vectors based on proximal optimization techniques, as well as a novel filter for recursive computation of statistical confidence regions. Simulation studies reveal that our algorithms outperform several existing point process filters in terms of trackability, goodness-of-fit and mean square error. We finally apply our filtering algorithms to experimentally recorded spiking data from the ferret primary auditory cortex during attentive behavior in a click rate discrimination task. Our analysis provides new insights into the time-course of the spectrotemporal receptive field plasticity of the auditory neurons.