 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiomimetic Frontend for Differentiable Audio Processing
Sep 13, 2024While models in audio and speech processing are becoming deeper and more end-to-end, they as a consequence need expensive training on large data, and are often brittle. We build on a classical model of human hearing and make it differentiable, so that we can combine traditional explainable biomimetic signal processing approaches with deep-learning frameworks. This allows us to arrive at an expressive and explainable model that is easily trained on modest amounts of data. We apply this model to audio processing tasks, including classification and enhancement. Results show that our differentiable model surpasses black-box approaches in terms of computational efficiency and robustness, even with little training data. We also discuss other potential applications.
Gaussian Process Models for HRTF based Sound-Source Localization and Active-Learning
Feb 11, 2015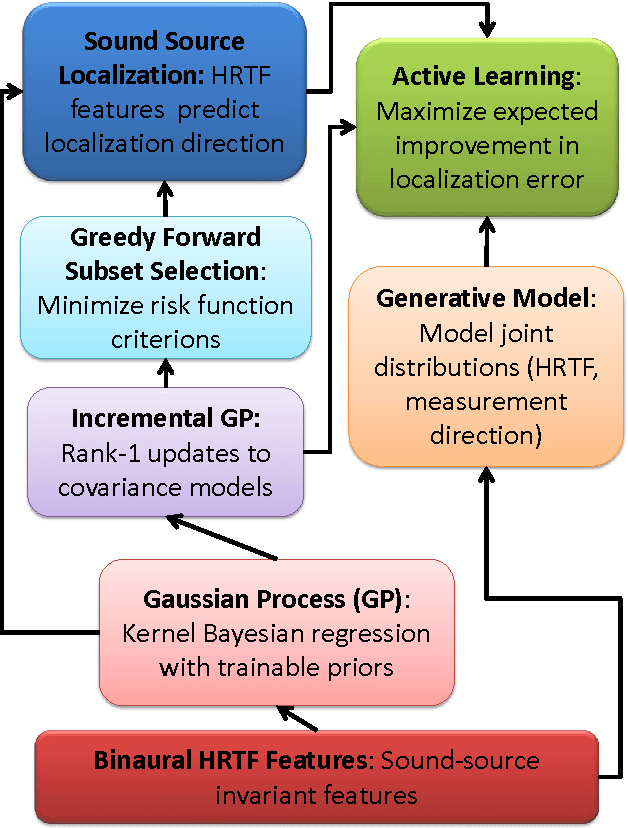
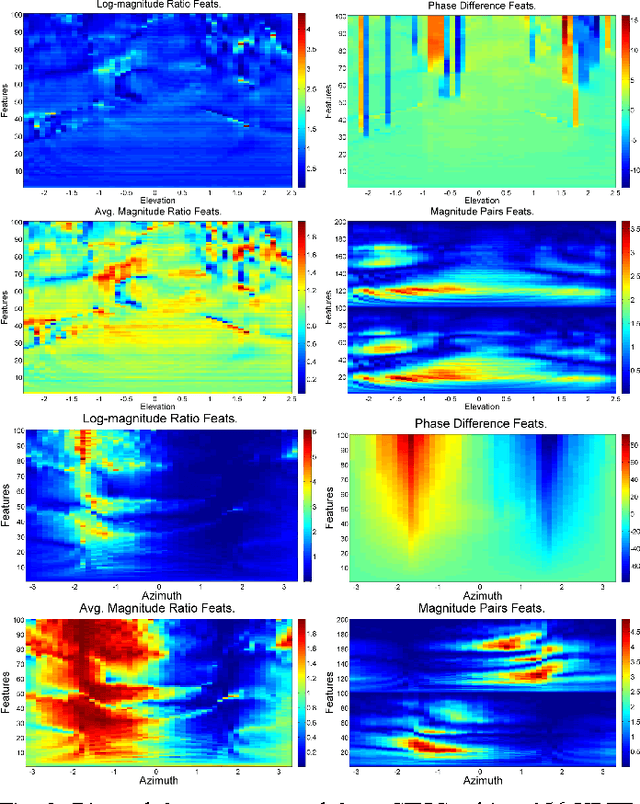
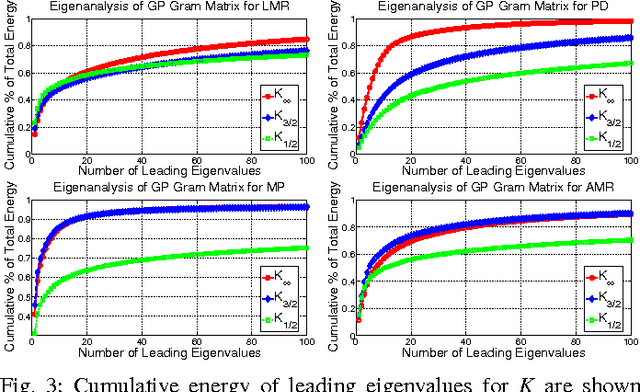

From a machine learning perspective, the human ability localize sounds can be modeled as a non-parametric and non-linear regression problem between binaural spectral features of sound received at the ears (input) and their sound-source directions (output). The input features can be summarized in terms of the individual's head-related transfer functions (HRTFs) which measure the spectral response between the listener's eardrum and an external point in $3$D. Based on these viewpoints, two related problems are considered: how can one achieve an optimal sampling of measurements for training sound-source localization (SSL) models, and how can SSL models be used to infer the subject's HRTFs in listening tests. First, we develop a class of binaural SSL models based on Gaussian process regression and solve a \emph{forward selection} problem that finds a subset of input-output samples that best generalize to all SSL directions. Second, we use an \emph{active-learning} approach that updates an online SSL model for inferring the subject's SSL errors via headphones and a graphical user interface. Experiments show that only a small fraction of HRTFs are required for $5^{\circ}$ localization accuracy and that the learned HRTFs are localized closer to their intended directions than non-individualized HRTFs.