 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGauss Circle Lattices with Geometric Convolutions for Synthesizing High Dimensional Image-Source Room Impulse Responses
Jun 03, 2026The image-source model (ISM) is a widely adopted method for efficiently simulating acoustic room impulse responses (RIRs) under specular reflection assumptions. Acoustic paths between source and receiver are traced to lattice points computed from successive reflections over bounding planes of the room. Rectangular rooms bound the total number of image-sources to be polynomial in the RIR's duration or distance $k$ equivalent, with degree equal the number of room dimensions $N$. Direct ISM simulations are therefore compute upper-bound by $O \left ( k^N \right )$, and consider only cases of $N \leq 3$ for tractability and real-world applications. This work proposes an alternative computational method that lowers the asymptotic compute bound to $O \left ( N k^2 \log k \right )$ for integer coordinates and room dimensions via reducing ISM lattice point counting to the classic Gauss circle problem (GCP). We extend the lattice counting model to frequency-dependent and reflection weighted image-sources in higher dimensions, relating solutions between successive dimensions via the convolution operator. Two constructions for realizing RIRs are presented, along with time-frequency controls, error and run-time analysis, and RIR statistics.
Constraint Optimized Multichannel Mixer-limiter Design
Jul 09, 2025Multichannel audio mixer and limiter designs are conventionally decoupled for content reproduction over loudspeaker arrays due to high computational complexity and run-time costs. We propose a coupled mixer-limiter-envelope design formulated as an efficient linear-constrained quadratic program that minimizes a distortion objective over multichannel gain variables subject to sample mixture constraints. Novel methods for asymmetric constant overlap-add window optimization, objective function approximation, variable and constraint reduction are presented. Experiments demonstrate distortion reduction of the coupled design, and computational trade-offs required for efficient real-time processing.
Constant Directivity Loudspeaker Beamforming
Jul 02, 2024Loudspeaker array beamforming is a common signal processing technique for acoustic directivity control and robust audio reproduction. Unlike their microphone counterpart, loudspeaker constraints are often heterogeneous due to arrayed transducers with varying operating ranges in frequency, acoustic-electrical sensitivity, efficiency, and directivity. This work proposes a frequency-regularization method for generalized Rayleigh quotient directivity specifications and two novel beamformer designs that optimize for maximum efficiency constant directivity (MECD) and maximum sensitivity constant directivity (MSCD). We derive fast converging and analytic solutions from their quadratic equality constrained quadratic program formulations. Experiments optimize generalized directivity index constrained beamformer designs for a full-band heterogeneous array.
Gaussian Process Models for HRTF based Sound-Source Localization and Active-Learning
Feb 11, 2015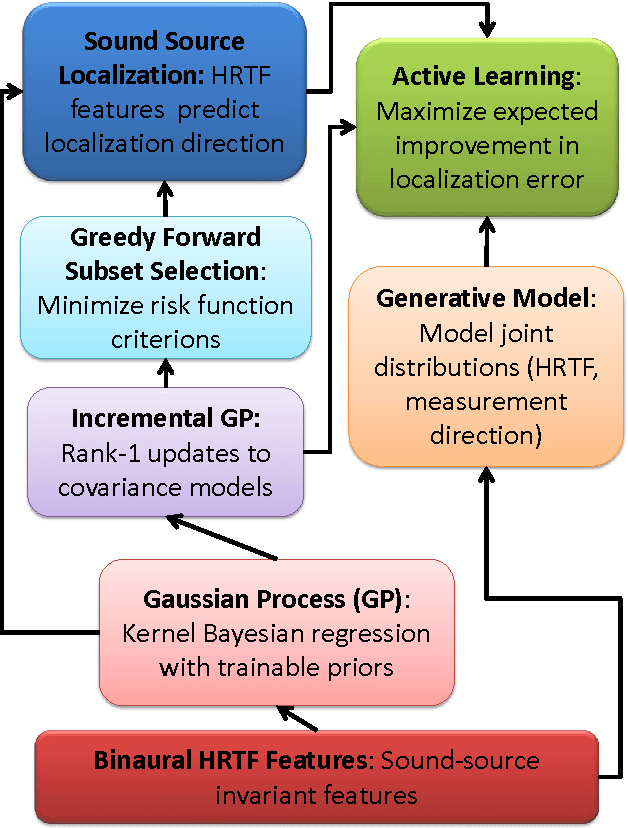
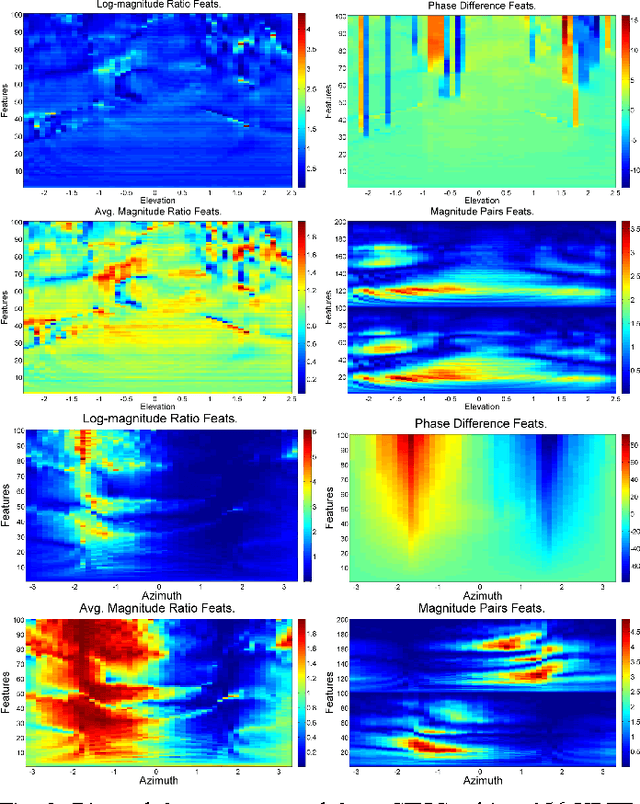
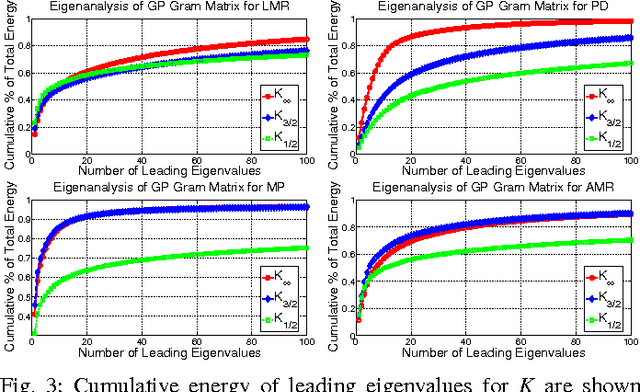

From a machine learning perspective, the human ability localize sounds can be modeled as a non-parametric and non-linear regression problem between binaural spectral features of sound received at the ears (input) and their sound-source directions (output). The input features can be summarized in terms of the individual's head-related transfer functions (HRTFs) which measure the spectral response between the listener's eardrum and an external point in $3$D. Based on these viewpoints, two related problems are considered: how can one achieve an optimal sampling of measurements for training sound-source localization (SSL) models, and how can SSL models be used to infer the subject's HRTFs in listening tests. First, we develop a class of binaural SSL models based on Gaussian process regression and solve a \emph{forward selection} problem that finds a subset of input-output samples that best generalize to all SSL directions. Second, we use an \emph{active-learning} approach that updates an online SSL model for inferring the subject's SSL errors via headphones and a graphical user interface. Experiments show that only a small fraction of HRTFs are required for $5^{\circ}$ localization accuracy and that the learned HRTFs are localized closer to their intended directions than non-individualized HRTFs.