 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-Attention Expert Prediction and Prefetching for Mixture-of-Experts Large Language Models
Nov 10, 2025Mixture-of-Experts (MoE) Large Language Models (LLMs) efficiently scale-up the model while keeping relatively low inference cost. As MoE models only activate part of the experts, related work has proposed expert prediction and caching methods to prefetch the experts for faster inference. However, existing approaches utilize the activations from the previous layer for prediction, incurring low accuracy and leave the first layer unoptimized. Applying complex layers or even training standalone networks for better prediction introduces high computation overhead. In this paper, we propose pre-attention expert prediction to achieve accurate and lightweight expert prefetching. The key insight is that some functions in LLMs are ranking-preserving, indicating that matching the ranking of selected experts using simple linear functions is possible. Therefore, we utilize the activations before the attention block in the same layer with 2 linear functions and ranking-aware loss to achieve accurate prediction, which also supports prefetching in the first layer. Our lightweight, pre-attention expert routers achieve 93.03% accuracy on DeepSeek V2 Lite, 94.69% on Qwen3-30B, and 97.62% on Phi-mini-MoE, showing about 15% improvement on absolute accuracy over the state-of-the-art methods.
FAT: An In-Memory Accelerator with Fast Addition for Ternary Weight Neural Networks
Jan 19, 2022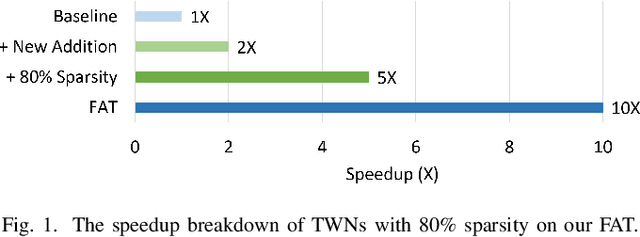
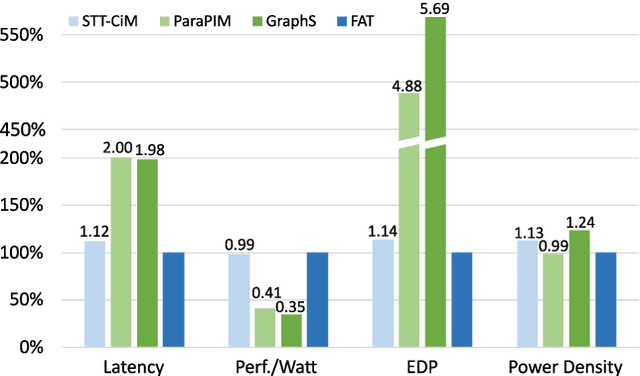

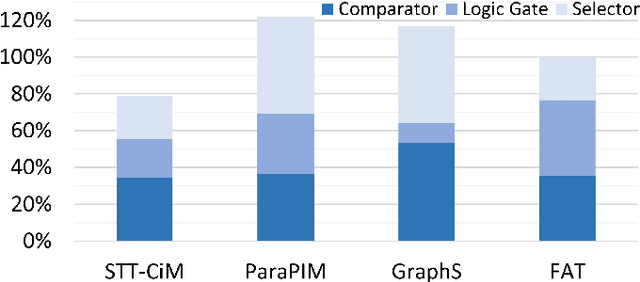
Convolutional Neural Networks (CNNs) demonstrate great performance in various applications but have high computational complexity. Quantization is applied to reduce the latency and storage cost of CNNs. Among the quantization methods, Binary and Ternary Weight Networks (BWNs and TWNs) have a unique advantage over 8-bit and 4-bit quantization. They replace the multiplication operations in CNNs with additions, which are favoured on In-Memory-Computing (IMC) devices. IMC acceleration for BWNs has been widely studied. However, though TWNs have higher accuracy and better sparsity, IMC acceleration for TWNs has limited research. TWNs on existing IMC devices are inefficient because the sparsity is not well utilized, and the addition operation is not efficient. In this paper, we propose FAT as a novel IMC accelerator for TWNs. First, we propose a Sparse Addition Control Unit, which utilizes the sparsity of TWNs to skip the null operations on zero weights. Second, we propose a fast addition scheme based on the memory Sense Amplifier to avoid the time overhead of both carry propagation and writing back the carry to the memory cells. Third, we further propose a Combined-Stationary data mapping to reduce the data movement of both activations and weights and increase the parallelism of memory columns. Simulation results show that for addition operations at the Sense Amplifier level, FAT achieves 2.00X speedup, 1.22X power efficiency and 1.22X area efficiency compared with State-Of-The-Art IMC accelerator ParaPIM. FAT achieves 10.02X speedup and 12.19X energy efficiency compared with ParaPIM on networks with 80% sparsity
Cross-filter compression for CNN inference acceleration
May 18, 2020
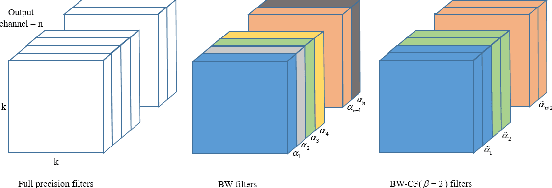
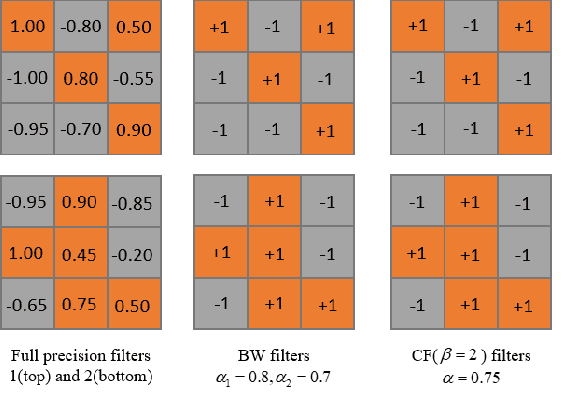
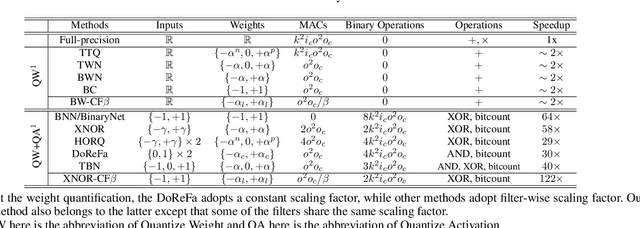
Convolution neural network demonstrates great capability for multiple tasks, such as image classification and many others. However, much resource is required to train a network. Hence much effort has been made to accelerate neural network by reducing precision of weights, activation, and gradient. However, these filter-wise quantification methods exist a natural upper limit, caused by the size of the kernel. Meanwhile, with the popularity of small kernel, the natural limit further decrease. To address this issue, we propose a new cross-filter compression method that can provide $\sim32\times$ memory savings and $122\times$ speed up in convolution operations. In our method, all convolution filters are quantized to given bits and spatially adjacent filters share the same scaling factor. Our compression method, based on Binary-Weight and XNOR-Net separately, is evaluated on CIFAR-10 and ImageNet dataset with widely used network structures, such as ResNet and VGG, and witness tolerable accuracy loss compared to state-of-the-art quantification methods.