 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Learngene via Stage-wise Weight Sharing for Initializing Variable-sized Models
Apr 25, 2024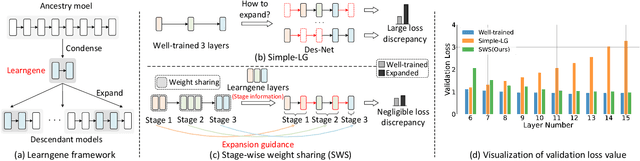
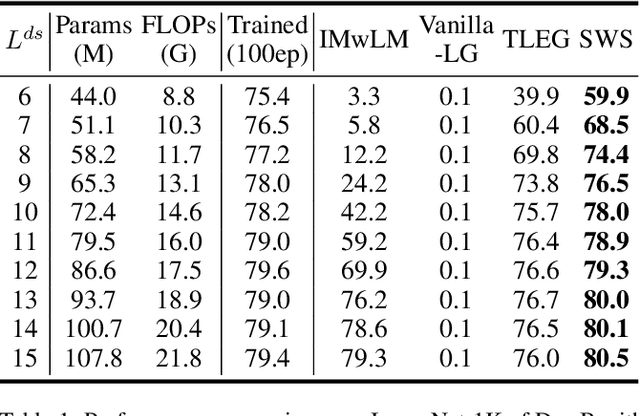
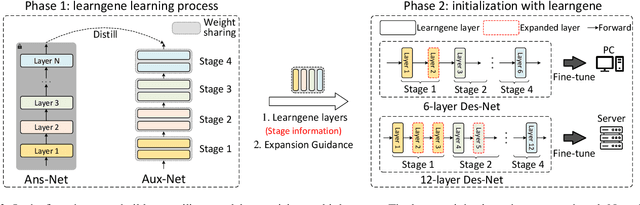
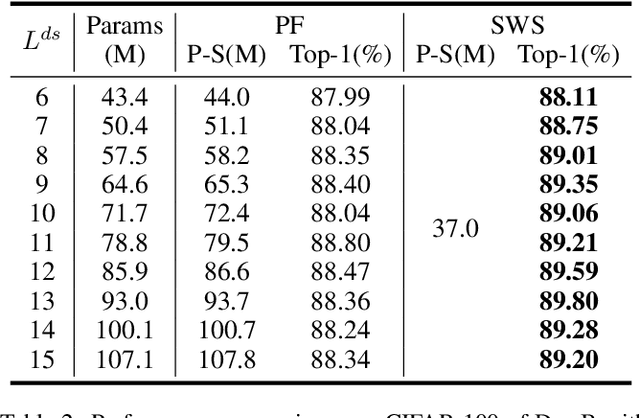
In practice, we usually need to build variable-sized models adapting for diverse resource constraints in different application scenarios, where weight initialization is an important step prior to training. The Learngene framework, introduced recently, firstly learns one compact part termed as learngene from a large well-trained model, after which learngene is expanded to initialize variable-sized models. In this paper, we start from analysing the importance of guidance for the expansion of well-trained learngene layers, inspiring the design of a simple but highly effective Learngene approach termed SWS (Stage-wise Weight Sharing), where both learngene layers and their learning process critically contribute to providing knowledge and guidance for initializing models at varying scales. Specifically, to learn learngene layers, we build an auxiliary model comprising multiple stages where the layer weights in each stage are shared, after which we train it through distillation. Subsequently, we expand these learngene layers containing stage information at their corresponding stage to initialize models of variable depths. Extensive experiments on ImageNet-1K demonstrate that SWS achieves consistent better performance compared to many models trained from scratch, while reducing around 6.6x total training costs. In some cases, SWS performs better only after 1 epoch tuning. When initializing variable-sized models adapting for different resource constraints, SWS achieves better results while reducing around 20x parameters stored to initialize these models and around 10x pre-training costs, in contrast to the pre-training and fine-tuning approach.