 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3DPalsyNet: A Facial Palsy Grading and Motion Recognition Framework using Fully 3D Convolutional Neural Networks
May 31, 2019

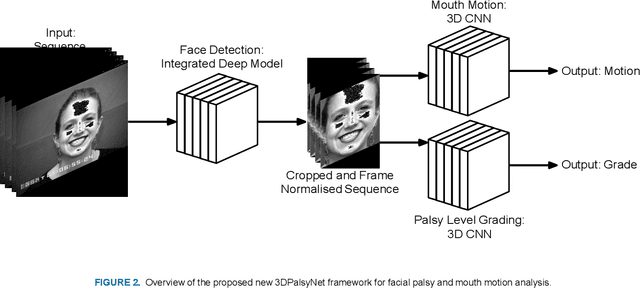
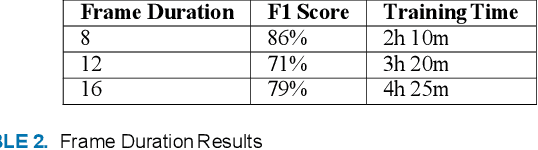
The capability to perform facial analysis from video sequences has significant potential to positively impact in many areas of life. One such area relates to the medical domain to specifically aid in the diagnosis and rehabilitation of patients with facial palsy. With this application in mind, this paper presents an end-to-end framework, named 3DPalsyNet, for the tasks of mouth motion recognition and facial palsy grading. 3DPalsyNet utilizes a 3D CNN architecture with a ResNet backbone for the prediction of these dynamic tasks. Leveraging transfer learning from a 3D CNNs pre-trained on the Kinetics data set for general action recognition, the model is modified to apply joint supervised learning using center and softmax loss concepts. 3DPalsyNet is evaluated on a test set consisting of individuals with varying ranges of facial palsy and mouth motions and the results have shown an attractive level of classification accuracy in these task of 82% and 86% respectively. The frame duration and the loss function affect was studied in terms of the predictive qualities of the proposed 3DPalsyNet, where it was found shorter frame duration's of 8 performed best for this specific task. Centre loss and softmax have shown improvements in spatio-temporal feature learning than softmax loss alone, this is in agreement with earlier work involving the spatial domain.