 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess is More: Facial Landmarks can Recognize a Spontaneous Smile
Oct 09, 2022
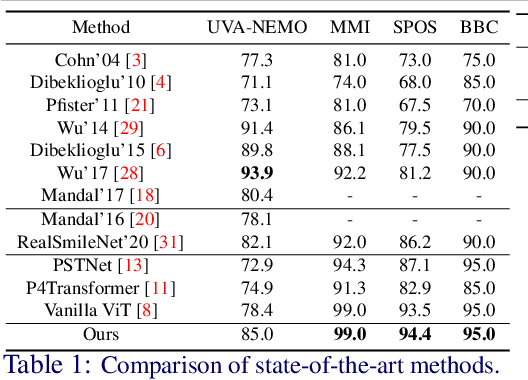

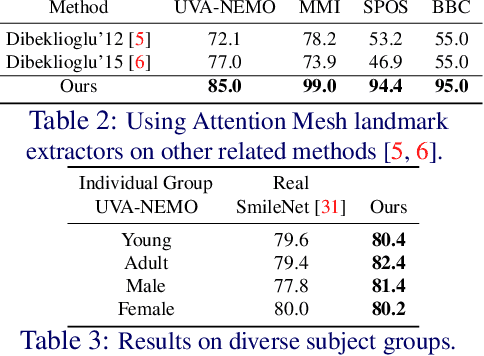
Smile veracity classification is a task of interpreting social interactions. Broadly, it distinguishes between spontaneous and posed smiles. Previous approaches used hand-engineered features from facial landmarks or considered raw smile videos in an end-to-end manner to perform smile classification tasks. Feature-based methods require intervention from human experts on feature engineering and heavy pre-processing steps. On the contrary, raw smile video inputs fed into end-to-end models bring more automation to the process with the cost of considering many redundant facial features (beyond landmark locations) that are mainly irrelevant to smile veracity classification. It remains unclear to establish discriminative features from landmarks in an end-to-end manner. We present a MeshSmileNet framework, a transformer architecture, to address the above limitations. To eliminate redundant facial features, our landmarks input is extracted from Attention Mesh, a pre-trained landmark detector. Again, to discover discriminative features, we consider the relativity and trajectory of the landmarks. For the relativity, we aggregate facial landmark that conceptually formats a curve at each frame to establish local spatial features. For the trajectory, we estimate the movements of landmark composed features across time by self-attention mechanism, which captures pairwise dependency on the trajectory of the same landmark. This idea allows us to achieve state-of-the-art performances on UVA-NEMO, BBC, MMI Facial Expression, and SPOS datasets.