 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning with Expected Error Reduction
Nov 17, 2022Active learning has been studied extensively as a method for efficient data collection. Among the many approaches in literature, Expected Error Reduction (EER) (Roy and McCallum) has been shown to be an effective method for active learning: select the candidate sample that, in expectation, maximally decreases the error on an unlabeled set. However, EER requires the model to be retrained for every candidate sample and thus has not been widely used for modern deep neural networks due to this large computational cost. In this paper we reformulate EER under the lens of Bayesian active learning and derive a computationally efficient version that can use any Bayesian parameter sampling method (such as arXiv:1506.02142). We then compare the empirical performance of our method using Monte Carlo dropout for parameter sampling against state of the art methods in the deep active learning literature. Experiments are performed on four standard benchmark datasets and three WILDS datasets (arXiv:2012.07421). The results indicate that our method outperforms all other methods except one in the data shift scenario: a model dependent, non-information theoretic method that requires an order of magnitude higher computational cost (arXiv:1906.03671).
Evaluating Generative Adversarial Networks on Explicitly Parameterized Distributions
Dec 27, 2018
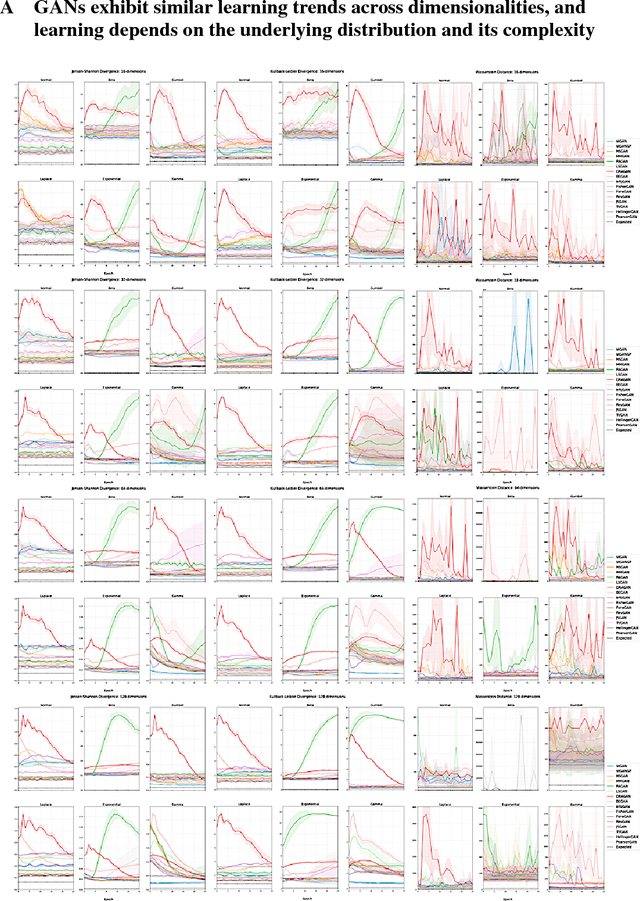
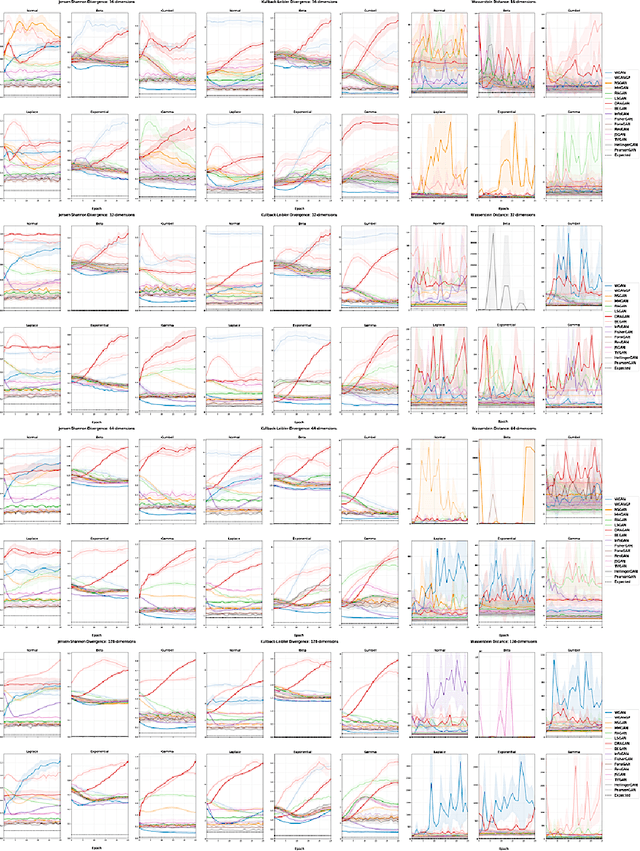
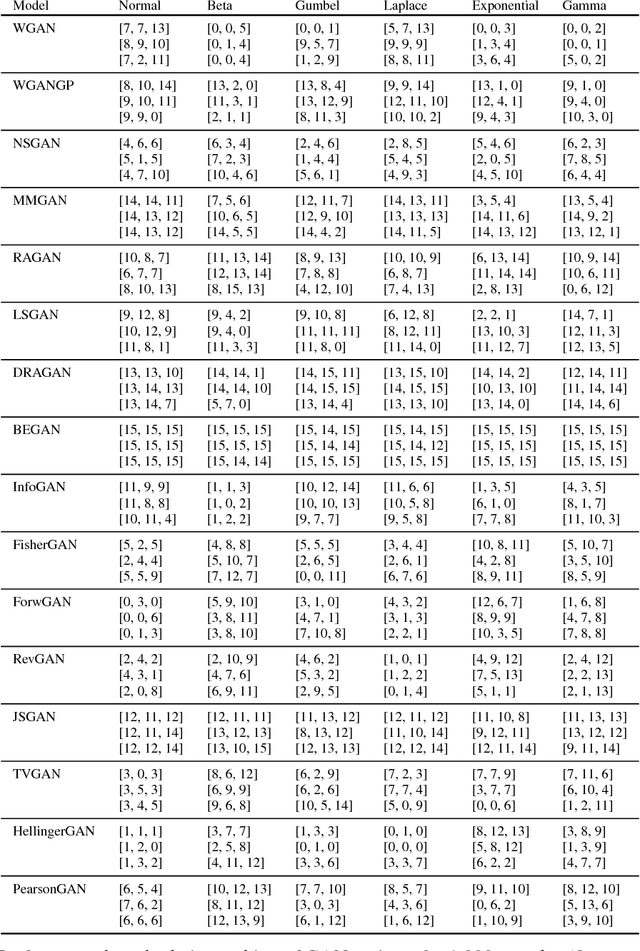
The true distribution parameterizations of commonly used image datasets are inaccessible. Rather than designing metrics for feature spaces with unknown characteristics, we propose to measure GAN performance by evaluating on explicitly parameterized, synthetic data distributions. As a case study, we examine the performance of 16 GAN variants on six multivariate distributions of varying dimensionalities and training set sizes. In this learning environment, we observe that: GANs exhibit similar performance trends across dimensionalities; learning depends on the underlying distribution and its complexity; the number of training samples can have a large impact on performance; evaluation and relative comparisons are metric-dependent; diverse sets of hyperparameters can produce a "best" result; and some GANs are more robust to hyperparameter changes than others. These observations both corroborate findings of previous GAN evaluation studies and make novel contributions regarding the relationship between size, complexity, and GAN performance.
Context is Key: New Approaches to Neural Coherence Modeling
Dec 06, 2018
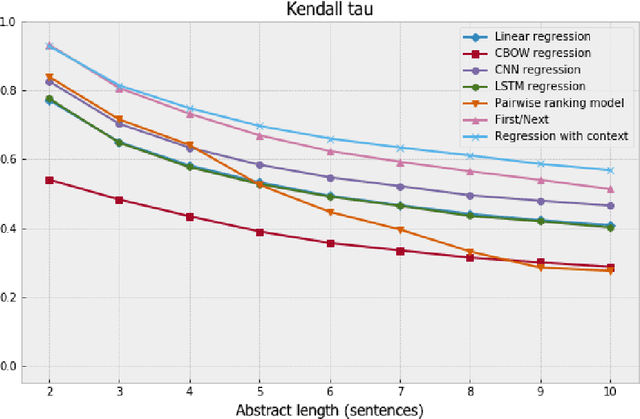
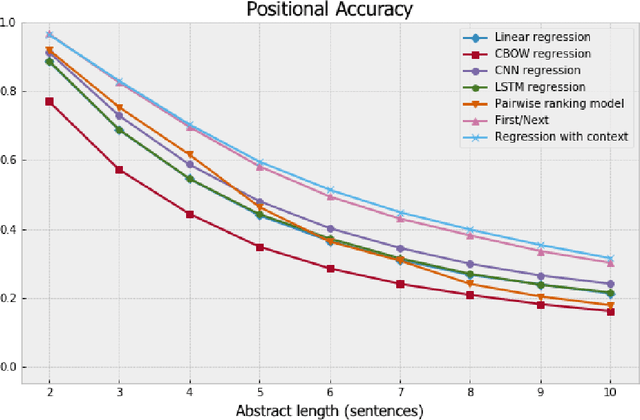
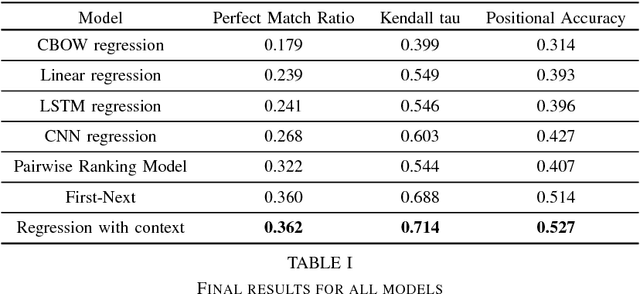
We formulate coherence modeling as a regression task and propose two novel methods to combine techniques from our setup with pairwise approaches. The first of our methods is a model that we call "first-next," which operates similarly to selection sorting but conditions decision-making on information about already-sorted sentences. The second consists of a technique for adding context to regression-based models by concatenating sentence-level representations with an encoding of its corresponding out-of-order paragraph. This latter model achieves Kendall-tau distance and positional accuracy scores that match or exceed the current state-of-the-art on these metrics. Our results suggest that many of the gains that come from more complex, machine-translation inspired approaches can be achieved with simpler, more efficient models.