 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffStyler: Diffusion-based Localized Image Style Transfer
Mar 27, 2024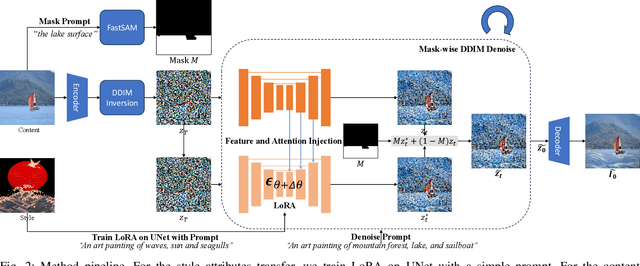
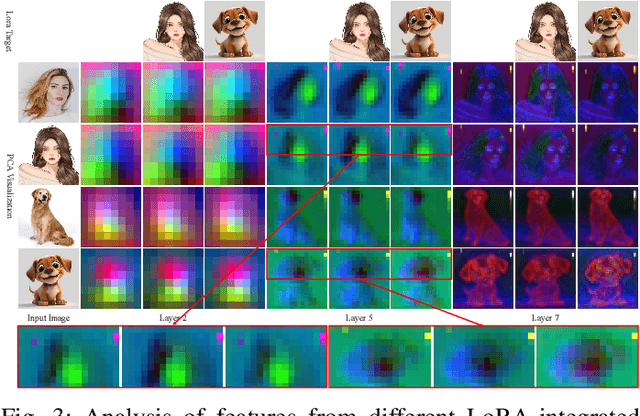

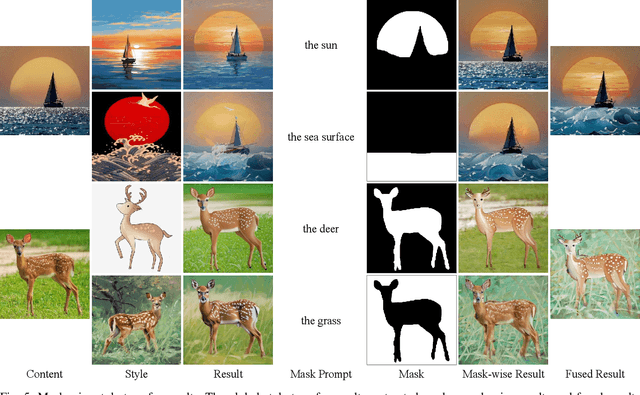
Image style transfer aims to imbue digital imagery with the distinctive attributes of style targets, such as colors, brushstrokes, shapes, whilst concurrently preserving the semantic integrity of the content. Despite the advancements in arbitrary style transfer methods, a prevalent challenge remains the delicate equilibrium between content semantics and style attributes. Recent developments in large-scale text-to-image diffusion models have heralded unprecedented synthesis capabilities, albeit at the expense of relying on extensive and often imprecise textual descriptions to delineate artistic styles. Addressing these limitations, this paper introduces DiffStyler, a novel approach that facilitates efficient and precise arbitrary image style transfer. DiffStyler lies the utilization of a text-to-image Stable Diffusion model-based LoRA to encapsulate the essence of style targets. This approach, coupled with strategic cross-LoRA feature and attention injection, guides the style transfer process. The foundation of our methodology is rooted in the observation that LoRA maintains the spatial feature consistency of UNet, a discovery that further inspired the development of a mask-wise style transfer technique. This technique employs masks extracted through a pre-trained FastSAM model, utilizing mask prompts to facilitate feature fusion during the denoising process, thereby enabling localized style transfer that preserves the original image's unaffected regions. Moreover, our approach accommodates multiple style targets through the use of corresponding masks. Through extensive experimentation, we demonstrate that DiffStyler surpasses previous methods in achieving a more harmonious balance between content preservation and style integration.
AniArtAvatar: Animatable 3D Art Avatar from a Single Image
Mar 26, 2024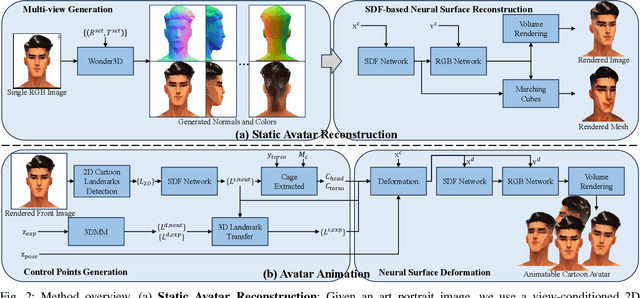



We present a novel approach for generating animatable 3D-aware art avatars from a single image, with controllable facial expressions, head poses, and shoulder movements. Unlike previous reenactment methods, our approach utilizes a view-conditioned 2D diffusion model to synthesize multi-view images from a single art portrait with a neutral expression. With the generated colors and normals, we synthesize a static avatar using an SDF-based neural surface. For avatar animation, we extract control points, transfer the motion with these points, and deform the implicit canonical space. Firstly, we render the front image of the avatar, extract the 2D landmarks, and project them to the 3D space using a trained SDF network. We extract 3D driving landmarks using 3DMM and transfer the motion to the avatar landmarks. To animate the avatar pose, we manually set the body height and bound the head and torso of an avatar with two cages. The head and torso can be animated by transforming the two cages. Our approach is a one-shot pipeline that can be applied to various styles. Experiments demonstrate that our method can generate high-quality 3D art avatars with desired control over different motions.
OPHAvatars: One-shot Photo-realistic Head Avatars
Jul 19, 2023
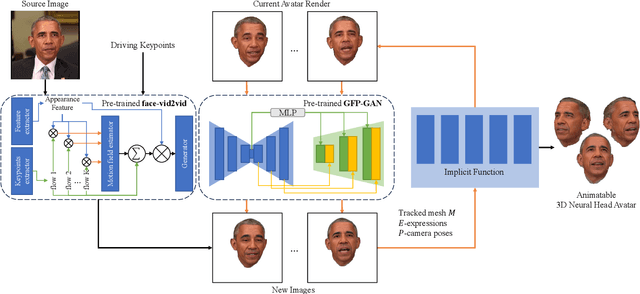


We propose a method for synthesizing photo-realistic digital avatars from only one portrait as the reference. Given a portrait, our method synthesizes a coarse talking head video using driving keypoints features. And with the coarse video, our method synthesizes a coarse talking head avatar with a deforming neural radiance field. With rendered images of the coarse avatar, our method updates the low-quality images with a blind face restoration model. With updated images, we retrain the avatar for higher quality. After several iterations, our method can synthesize a photo-realistic animatable 3D neural head avatar. The motivation of our method is deformable neural radiance field can eliminate the unnatural distortion caused by the image2video method. Our method outperforms state-of-the-art methods in quantitative and qualitative studies on various subjects.
Instruct-Video2Avatar: Video-to-Avatar Generation with Instructions
Jun 05, 2023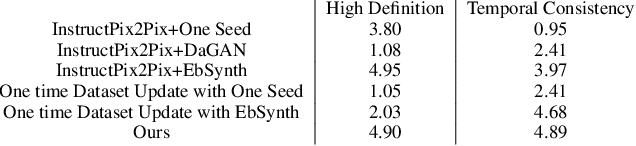
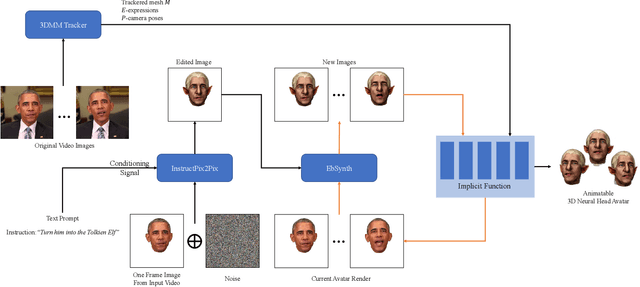


We propose a method for synthesizing edited photo-realistic digital avatars with text instructions. Given a short monocular RGB video and text instructions, our method uses an image-conditioned diffusion model to edit one head image and uses the video stylization method to accomplish the editing of other head images. Through iterative training and update (three times or more), our method synthesizes edited photo-realistic animatable 3D neural head avatars with a deformable neural radiance field head synthesis method. In quantitative and qualitative studies on various subjects, our method outperforms state-of-the-art methods.
Interactive Geometry Editing of Neural Radiance Fields
Apr 03, 2023In this paper, we propose a method that enables interactive geometry editing for neural radiance fields manipulation. We use two proxy cages(inner cage and outer cage) to edit a scene. The inner cage defines the operation target, and the outer cage defines the adjustment space. Various operations apply to the two cages. After cage selection, operations on the inner cage lead to the desired transformation of the inner cage and adjustment of the outer cage. Users can edit the scene with translation, rotation, scaling, or combinations. The operations on the corners and edges of the cage are also supported. Our method does not need any explicit 3D geometry representations. The interactive geometry editing applies directly to the implicit neural radiance fields. Extensive experimental results demonstrate the effectiveness of our approach.
Instant Neural Radiance Fields Stylization
Mar 29, 2023We present Instant Neural Radiance Fields Stylization, a novel approach for multi-view image stylization for the 3D scene. Our approach models a neural radiance field based on neural graphics primitives, which use a hash table-based position encoder for position embedding. We split the position encoder into two parts, the content and style sub-branches, and train the network for normal novel view image synthesis with the content and style targets. In the inference stage, we execute AdaIN to the output features of the position encoder, with content and style voxel grid features as reference. With the adjusted features, the stylization of novel view images could be obtained. Our method extends the style target from style images to image sets of scenes and does not require additional network training for stylization. Given a set of images of 3D scenes and a style target(a style image or another set of 3D scenes), our method can generate stylized novel views with a consistent appearance at various view angles in less than 10 minutes on modern GPU hardware. Extensive experimental results demonstrate the validity and superiority of our method.