Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruct-Video2Avatar: Video-to-Avatar Generation with Instructions
Paper and Code
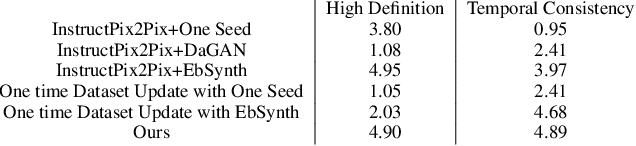
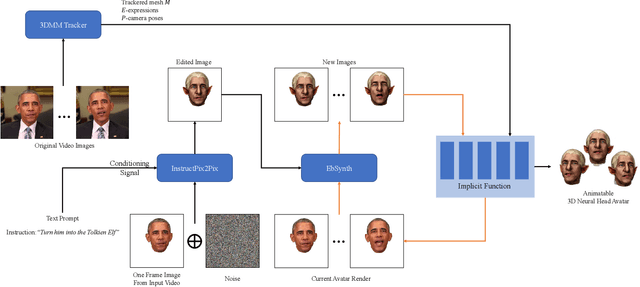


We propose a method for synthesizing edited photo-realistic digital avatars with text instructions. Given a short monocular RGB video and text instructions, our method uses an image-conditioned diffusion model to edit one head image and uses the video stylization method to accomplish the editing of other head images. Through iterative training and update (three times or more), our method synthesizes edited photo-realistic animatable 3D neural head avatars with a deformable neural radiance field head synthesis method. In quantitative and qualitative studies on various subjects, our method outperforms state-of-the-art methods.
View paper on