 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPHAvatars: One-shot Photo-realistic Head Avatars
Paper and Code

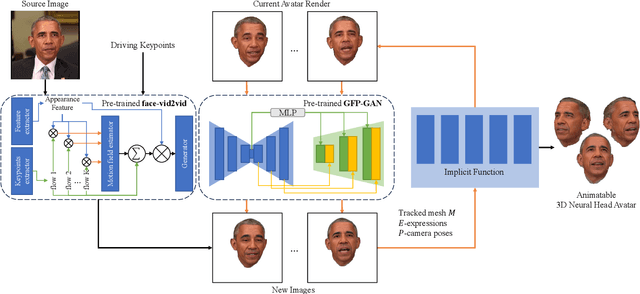


We propose a method for synthesizing photo-realistic digital avatars from only one portrait as the reference. Given a portrait, our method synthesizes a coarse talking head video using driving keypoints features. And with the coarse video, our method synthesizes a coarse talking head avatar with a deforming neural radiance field. With rendered images of the coarse avatar, our method updates the low-quality images with a blind face restoration model. With updated images, we retrain the avatar for higher quality. After several iterations, our method can synthesize a photo-realistic animatable 3D neural head avatar. The motivation of our method is deformable neural radiance field can eliminate the unnatural distortion caused by the image2video method. Our method outperforms state-of-the-art methods in quantitative and qualitative studies on various subjects.