 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrcheo: A Modular Full-Stack Platform for Conversational Search
Feb 16, 2026Conversational search (CS) requires a complex software engineering pipeline that integrates query reformulation, ranking, and response generation. CS researchers currently face two barriers: the lack of a unified framework for efficiently sharing contributions with the community, and the difficulty of deploying end-to-end prototypes needed for user evaluation. We introduce Orcheo, an open-source platform designed to bridge this gap. Orcheo offers three key advantages: (i) A modular architecture promotes component reuse through single-file node modules, facilitating sharing and reproducibility in CS research; (ii) Production-ready infrastructure bridges the prototype-to-system gap via dual execution modes, secure credential management, and execution telemetry, with built-in AI coding support that lowers the learning curve; (iii) Starter-kit assets include 50+ off-the-shelf components for query understanding, ranking, and response generation, enabling the rapid bootstrapping of complete CS pipelines. We describe the framework architecture and validate Orcheo's utility through case studies that highlight modularity and ease of use. Orcheo is released as open source under the MIT License at https://github.com/ShaojieJiang/orcheo.
A Simple Contrastive Learning Objective for Alleviating Neural Text Degeneration
May 19, 2022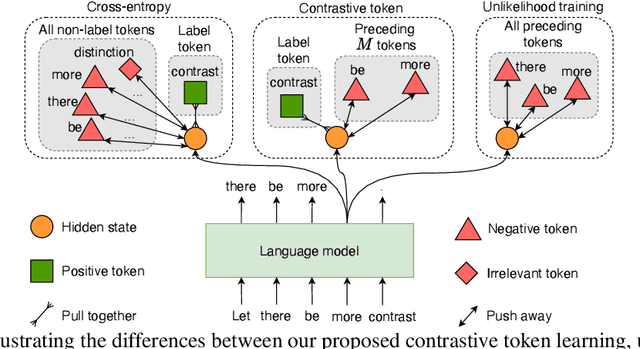
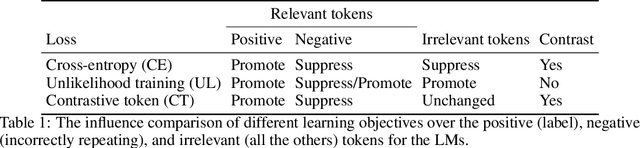
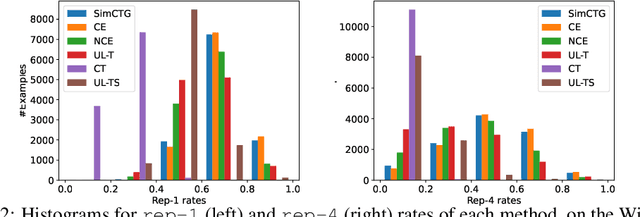
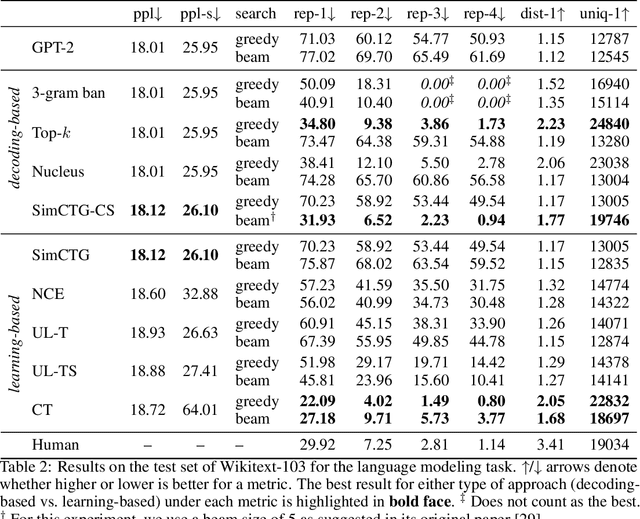
The cross-entropy objective has proved to be an all-purpose training objective for autoregressive language models (LMs). However, without considering the penalization of problematic tokens, LMs trained using cross-entropy exhibit text degeneration. To address this, unlikelihood training has been proposed to reduce the probability of unlikely tokens predicted by LMs. But unlikelihood does not consider the relationship between the label tokens and unlikely token candidates, thus showing marginal improvements in degeneration. We propose a new contrastive token learning objective that inherits the advantages of cross-entropy and unlikelihood training and avoids their limitations. The key idea is to teach a LM to generate high probabilities for label tokens and low probabilities of negative candidates. Comprehensive experiments on language modeling and open-domain dialogue generation tasks show that the proposed contrastive token objective yields much less repetitive texts, with a higher generation quality than baseline approaches, achieving the new state-of-the-art performance on text degeneration.
TLDR: Token Loss Dynamic Reweighting for Reducing Repetitive Utterance Generation
Apr 09, 2020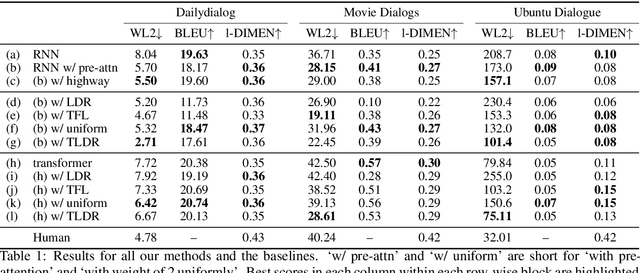

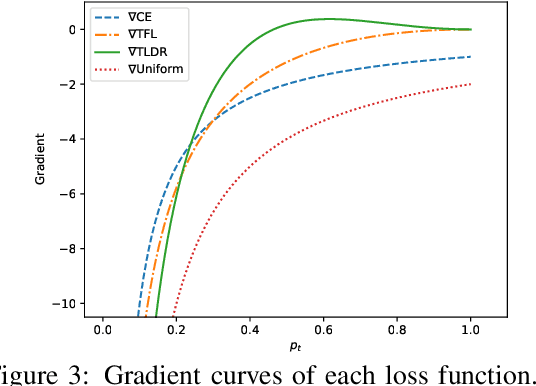

Natural Language Generation (NLG) models are prone to generating repetitive utterances. In this work, we study the repetition problem for encoder-decoder models, using both recurrent neural network (RNN) and transformer architectures. To this end, we consider the chit-chat task, where the problem is more prominent than in other tasks that need encoder-decoder architectures. We first study the influence of model architectures. By using pre-attention and highway connections for RNNs, we manage to achieve lower repetition rates. However, this method does not generalize to other models such as transformers. We hypothesize that the deeper reason is that in the training corpora, there are hard tokens that are more difficult for a generative model to learn than others and, once learning has finished, hard tokens are still under-learned, so that repetitive generations are more likely to happen. Based on this hypothesis, we propose token loss dynamic reweighting (TLDR) that applies differentiable weights to individual token losses. By using higher weights for hard tokens and lower weights for easy tokens, NLG models are able to learn individual tokens at different paces. Experiments on chit-chat benchmark datasets show that TLDR is more effective in repetition reduction for both RNN and transformer architectures than baselines using different weighting functions.
Improving Neural Response Diversity with Frequency-Aware Cross-Entropy Loss
Feb 25, 2019

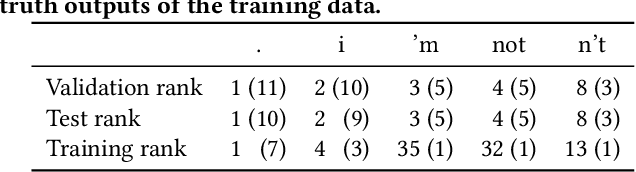

Sequence-to-Sequence (Seq2Seq) models have achieved encouraging performance on the dialogue response generation task. However, existing Seq2Seq-based response generation methods suffer from a low-diversity problem: they frequently generate generic responses, which make the conversation less interesting. In this paper, we address the low-diversity problem by investigating its connection with model over-confidence reflected in predicted distributions. Specifically, we first analyze the influence of the commonly used Cross-Entropy (CE) loss function, and find that the CE loss function prefers high-frequency tokens, which results in low-diversity responses. We then propose a Frequency-Aware Cross-Entropy (FACE) loss function that improves over the CE loss function by incorporating a weighting mechanism conditioned on token frequency. Extensive experiments on benchmark datasets show that the FACE loss function is able to substantially improve the diversity of existing state-of-the-art Seq2Seq response generation methods, in terms of both automatic and human evaluations.
Why are Sequence-to-Sequence Models So Dull? Understanding the Low-Diversity Problem of Chatbots
Sep 06, 2018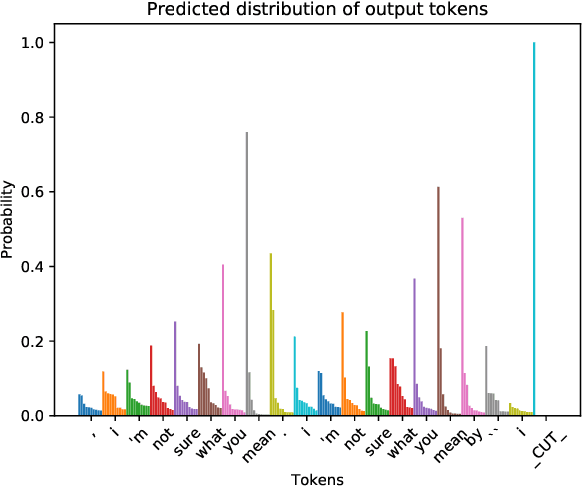

Diversity is a long-studied topic in information retrieval that usually refers to the requirement that retrieved results should be non-repetitive and cover different aspects. In a conversational setting, an additional dimension of diversity matters: an engaging response generation system should be able to output responses that are diverse and interesting. Sequence-to-sequence (Seq2Seq) models have been shown to be very effective for response generation. However, dialogue responses generated by Seq2Seq models tend to have low diversity. In this paper, we review known sources and existing approaches to this low-diversity problem. We also identify a source of low diversity that has been little studied so far, namely model over-confidence. We sketch several directions for tackling model over-confidence and, hence, the low-diversity problem, including confidence penalties and label smoothing.