 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy are Sequence-to-Sequence Models So Dull? Understanding the Low-Diversity Problem of Chatbots
Paper and Code
Sep 06, 2018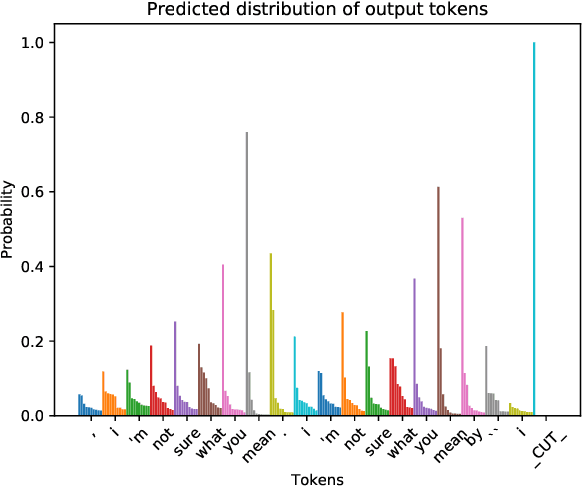

Diversity is a long-studied topic in information retrieval that usually refers to the requirement that retrieved results should be non-repetitive and cover different aspects. In a conversational setting, an additional dimension of diversity matters: an engaging response generation system should be able to output responses that are diverse and interesting. Sequence-to-sequence (Seq2Seq) models have been shown to be very effective for response generation. However, dialogue responses generated by Seq2Seq models tend to have low diversity. In this paper, we review known sources and existing approaches to this low-diversity problem. We also identify a source of low diversity that has been little studied so far, namely model over-confidence. We sketch several directions for tackling model over-confidence and, hence, the low-diversity problem, including confidence penalties and label smoothing.