 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End and Self-Supervised Learning for ComParE 2022 Stuttering Sub-Challenge
Jul 20, 2022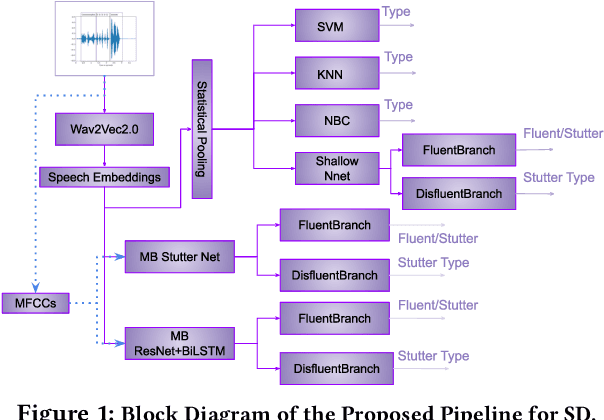
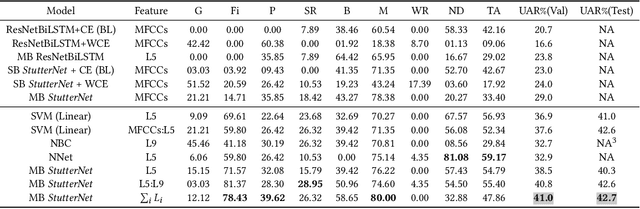
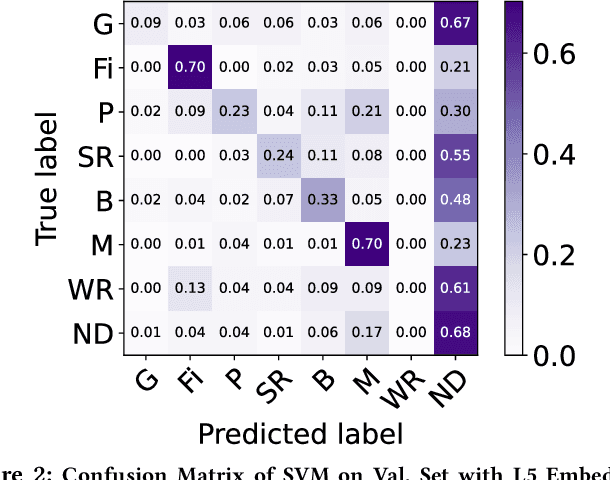

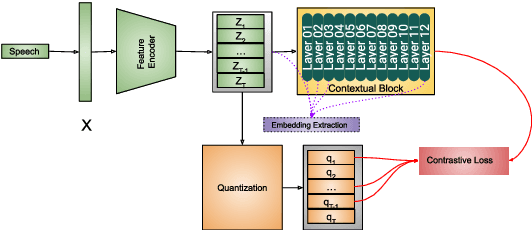
In this paper, we present end-to-end and speech embedding based systems trained in a self-supervised fashion to participate in the ACM Multimedia 2022 ComParE Challenge, specifically the stuttering sub-challenge. In particular, we exploit the embeddings from the pre-trained Wav2Vec2.0 model for stuttering detection (SD) on the KSoF dataset. After embedding extraction, we benchmark with several methods for SD. Our proposed self-supervised based SD system achieves a UAR of 36.9% and 41.0% on validation and test sets respectively, which is 31.32% (validation set) and 1.49% (test set) higher than the best (DeepSpectrum) challenge baseline (CBL). Moreover, we show that concatenating layer embeddings with Mel-frequency cepstral coefficients (MFCCs) features further improves the UAR of 33.81% and 5.45% on validation and test sets respectively over the CBL. Finally, we demonstrate that the summing information across all the layers of Wav2Vec2.0 surpasses the CBL by a relative margin of 45.91% and 5.69% on validation and test sets respectively. Grand-challenge: Computational Paralinguistics ChallengE
Robust Stuttering Detection via Multi-task and Adversarial Learning
Apr 04, 2022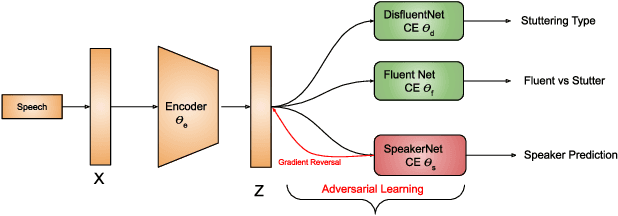
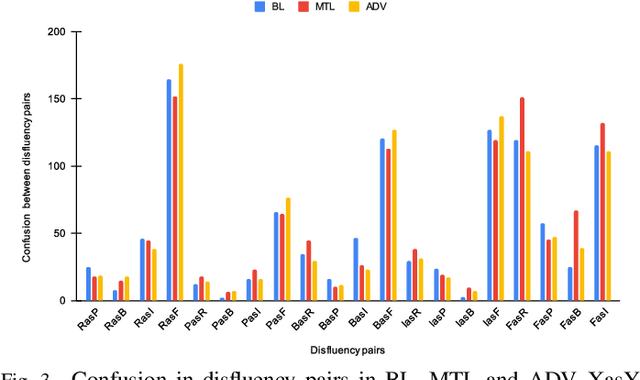
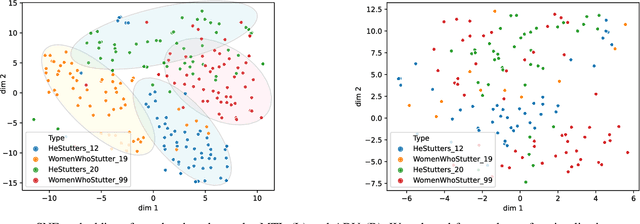
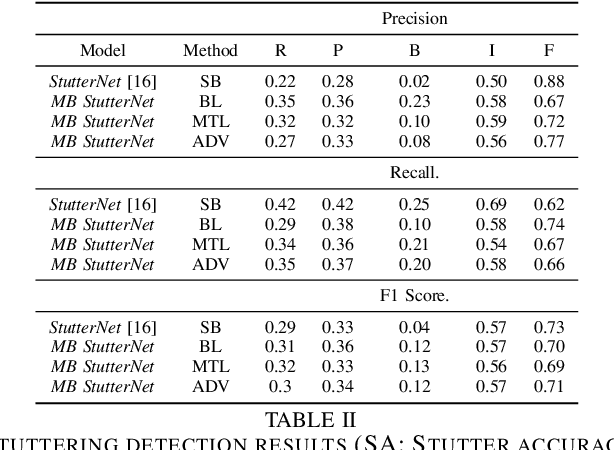
By automatic detection and identification of stuttering, speech pathologists can track the progression of disfluencies of persons who stutter (PWS). In this paper, we investigate the impact of multi-task (MTL) and adversarial learning (ADV) to learn robust stutter features. This is the first-ever preliminary study where MTL and ADV have been employed in stuttering identification (SI). We evaluate our system on the SEP-28k stuttering dataset consisting of 20 hours (approx) of data from 385 podcasts. Our methods show promising results and outperform the baseline in various disfluency classes. We achieve up to 10%, 6.78%, and 2% improvement in repetitions, blocks, and interjections respectively over the baseline.
Introducing ECAPA-TDNN and Wav2Vec2.0 Embeddings to Stuttering Detection
Apr 04, 2022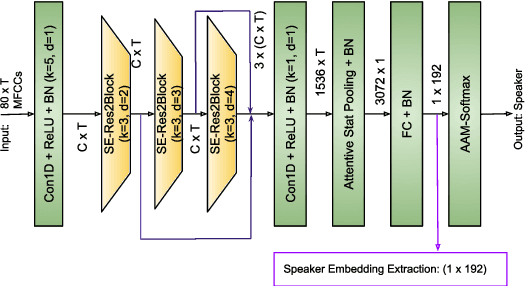
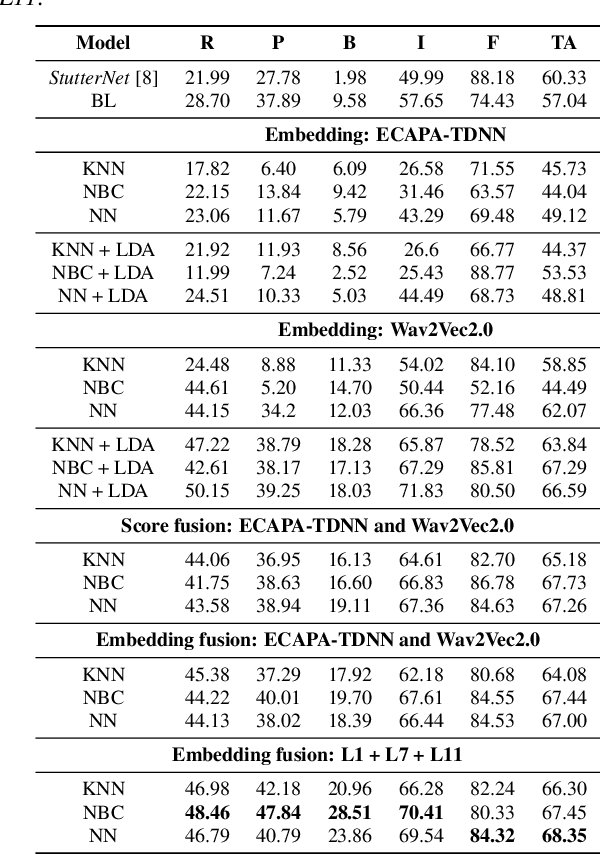

The adoption of advanced deep learning (DL) architecture in stuttering detection (SD) tasks is challenging due to the limited size of the available datasets. To this end, this work introduces the application of speech embeddings extracted with pre-trained deep models trained on massive audio datasets for different tasks. In particular, we explore audio representations obtained using emphasized channel attention, propagation, and aggregation-time-delay neural network (ECAPA-TDNN) and Wav2Vec2.0 model trained on VoxCeleb and LibriSpeech datasets respectively. After extracting the embeddings, we benchmark with several traditional classifiers, such as a k-nearest neighbor, Gaussian naive Bayes, and neural network, for the stuttering detection tasks. In comparison to the standard SD system trained only on the limited SEP-28k dataset, we obtain a relative improvement of 16.74% in terms of overall accuracy over baseline. Finally, we have shown that combining two embeddings and concatenating multiple layers of Wav2Vec2.0 can further improve SD performance up to 1% and 2.64% respectively.
Machine Learning for Stuttering Identification: Review, Challenges & Future Directions
Jul 12, 2021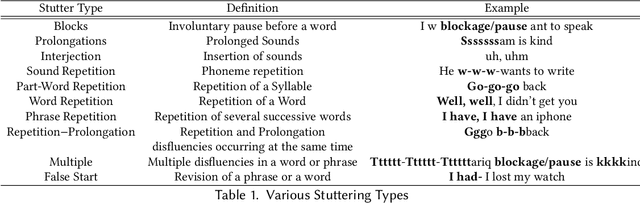
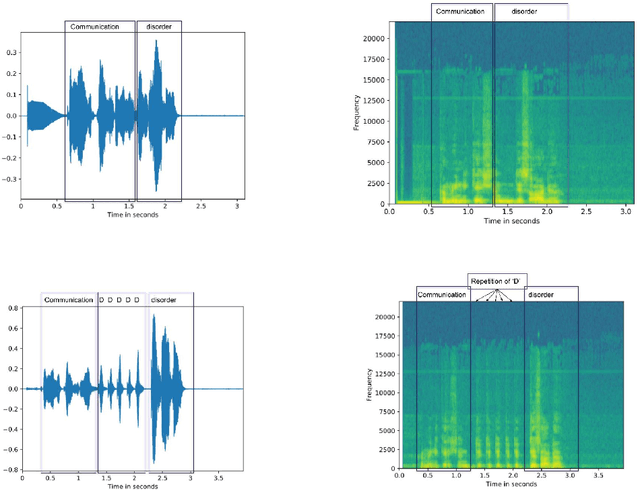
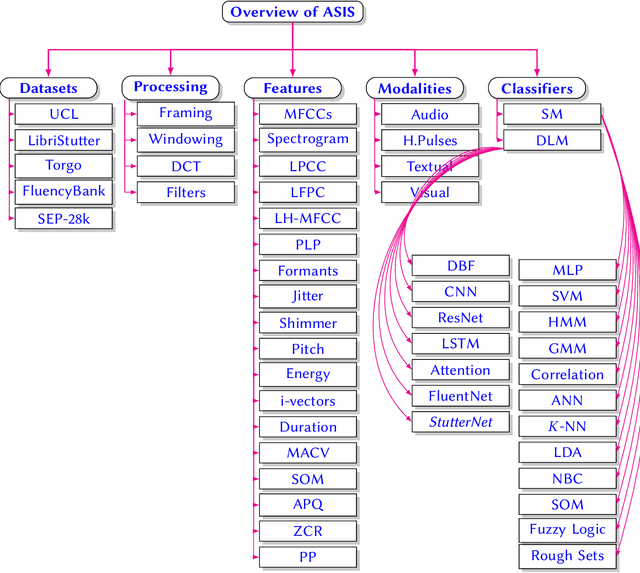
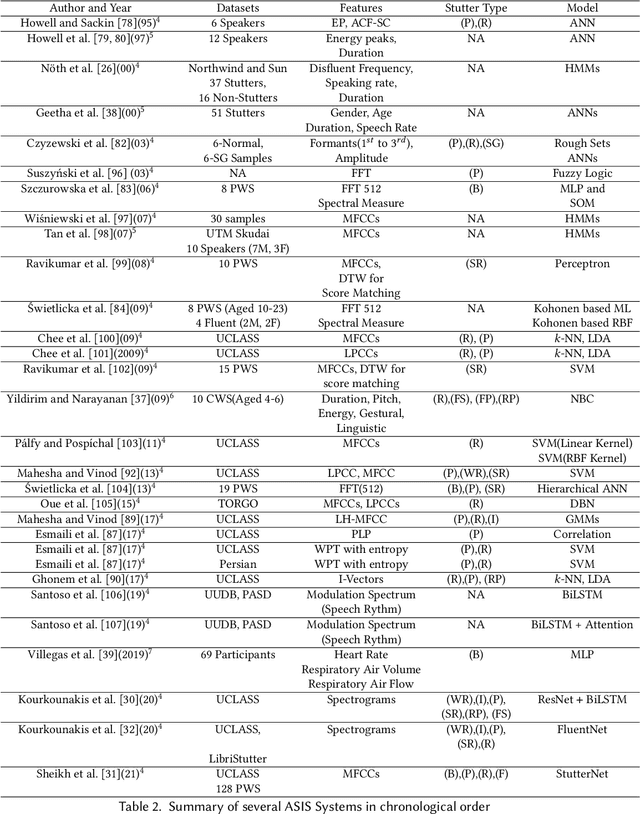
Stuttering is a speech disorder during which the flow of speech is interrupted by involuntary pauses and repetition of sounds. Stuttering identification is an interesting interdisciplinary domain research problem which involves pathology, psychology, acoustics, and signal processing that makes it hard and complicated to detect. Recent developments in machine and deep learning have dramatically revolutionized speech domain, however minimal attention has been given to stuttering identification. This work fills the gap by trying to bring researchers together from interdisciplinary fields. In this paper, we review comprehensively acoustic features, statistical and deep learning based stuttering/disfluency classification methods. We also present several challenges and possible future directions.