 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing ECAPA-TDNN and Wav2Vec2.0 Embeddings to Stuttering Detection
Paper and Code
Apr 04, 2022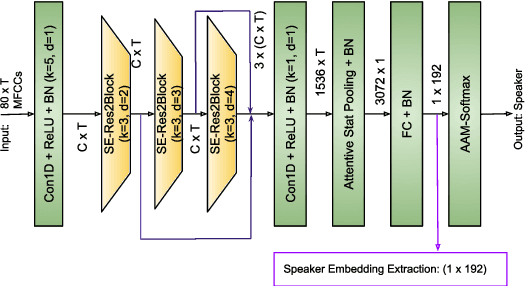
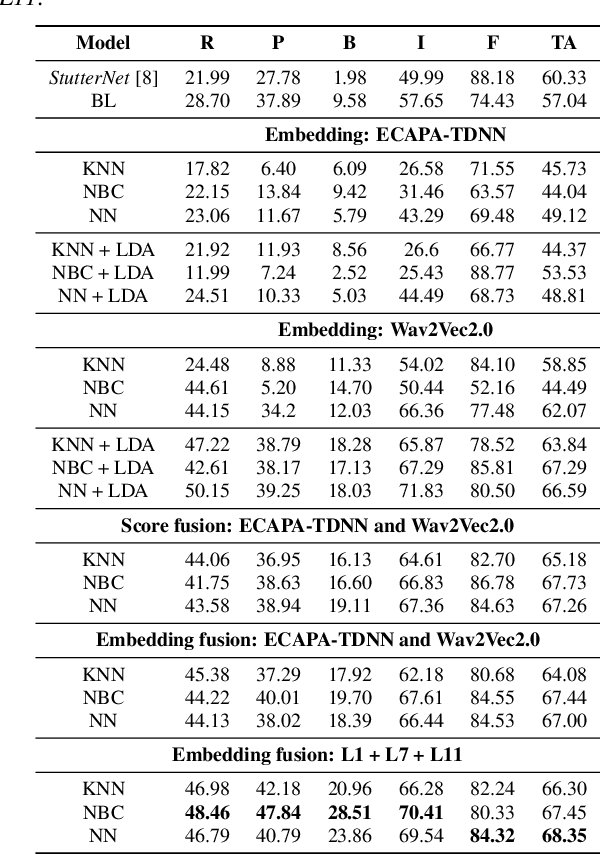
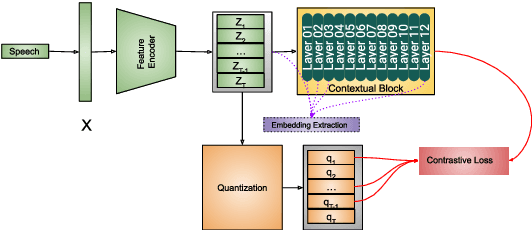

The adoption of advanced deep learning (DL) architecture in stuttering detection (SD) tasks is challenging due to the limited size of the available datasets. To this end, this work introduces the application of speech embeddings extracted with pre-trained deep models trained on massive audio datasets for different tasks. In particular, we explore audio representations obtained using emphasized channel attention, propagation, and aggregation-time-delay neural network (ECAPA-TDNN) and Wav2Vec2.0 model trained on VoxCeleb and LibriSpeech datasets respectively. After extracting the embeddings, we benchmark with several traditional classifiers, such as a k-nearest neighbor, Gaussian naive Bayes, and neural network, for the stuttering detection tasks. In comparison to the standard SD system trained only on the limited SEP-28k dataset, we obtain a relative improvement of 16.74% in terms of overall accuracy over baseline. Finally, we have shown that combining two embeddings and concatenating multiple layers of Wav2Vec2.0 can further improve SD performance up to 1% and 2.64% respectively.