 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing ECG Diagnosis Using Reinforcement Learning on Global Waveform Variations Related to P Wave and PR Interval
Jan 10, 2024The reliable diagnosis of cardiac conditions through electrocardiogram (ECG) analysis critically depends on accurately detecting P waves and measuring the PR interval. However, achieving consistent and generalizable diagnoses across diverse populations presents challenges due to the inherent global variations observed in ECG signals. This paper is focused on applying the Q learning reinforcement algorithm to the various ECG datasets available in the PhysioNet/Computing in Cardiology Challenge (CinC). Five ECG beats, including Normal Sinus Rhythm, Atrial Flutter, Atrial Fibrillation, 1st Degree Atrioventricular Block, and Left Atrial Enlargement, are included to study variations of P waves and PR Interval on Lead II and Lead V1. Q-Agent classified 71,672 beat samples in 8,867 patients with an average accuracy of 90.4% and only 9.6% average hamming loss over misclassification. The average classification time at the 100th episode containing around 40,000 samples is 0.04 seconds. An average training reward of 344.05 is achieved at an alpha, gamma, and SoftMax temperature rate of 0.001, 0.9, and 0.1, respectively.
Transfer Learning for Improving Speech Emotion Classification Accuracy
Mar 26, 2018
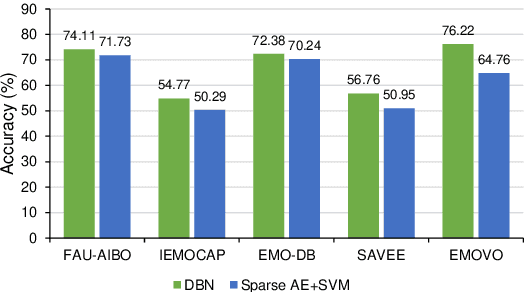


The majority of existing speech emotion recognition research focuses on automatic emotion detection using training and testing data from same corpus collected under the same conditions. The performance of such systems has been shown to drop significantly in cross-corpus and cross-language scenarios. To address the problem, this paper exploits a transfer learning technique to improve the performance of speech emotion recognition systems that is novel in cross-language and cross-corpus scenarios. Evaluations on five different corpora in three different languages show that Deep Belief Networks (DBNs) offer better accuracy than previous approaches on cross-corpus emotion recognition, relative to a Sparse Autoencoder and SVM baseline system. Results also suggest that using a large number of languages for training and using a small fraction of the target data in training can significantly boost accuracy compared with baseline also for the corpus with limited training examples.