 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Doubly Regularized Linear Discriminant Analysis Classifier with Automatic Parameter Selection
Apr 28, 2020


Linear discriminant analysis (LDA) based classifiers tend to falter in many practical settings where the training data size is smaller than, or comparable to, the number of features. As a remedy, regularized LDA (RLDA) methods have been proposed. However, the classification performance of these methods vary depending on the size of training and test data. In this paper, we propose a doubly regularized LDA classifier that we denote as R2LDA. In the proposed R2LDA approach, two regularization operations are carried out; one involving only the training data set, while the other also includes the given test data sample. The proposed R2LDA algorithm, unlike the classical RLDA techniques, caters for errors due to training data as well as the possible noise in the test data. Choosing the two regularization parameters in R2LDA can be automated through existing methods based on least squares (LS). Particularly, we show that a constrained perturbation regularization approach (COPRA) is well suited for the regularization parameter selection task needed for the proposed R2LDA classifier. Results obtained from both synthetic and real data demonstrate the consistency and effectiveness of the proposed R2LDA-COPRA classifier, especially in scenarios involving noisy test data.
Pioneer dataset and automatic recognition of Urdu handwritten characters using a deep autoencoder and convolutional neural network
Dec 17, 2019
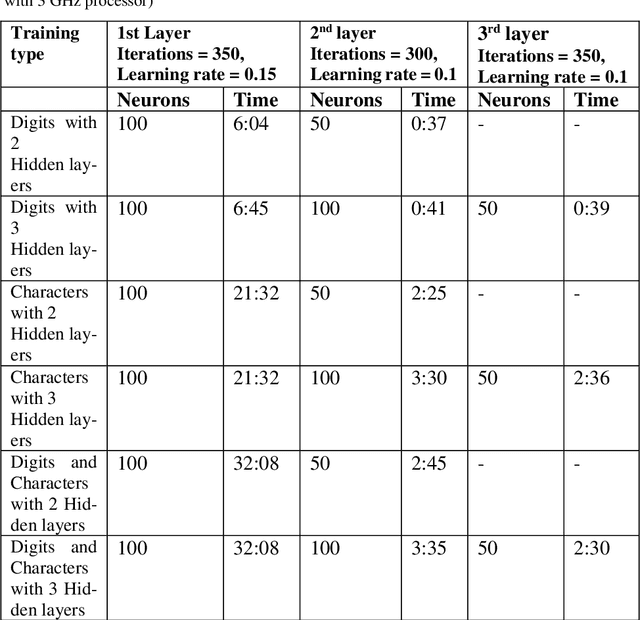
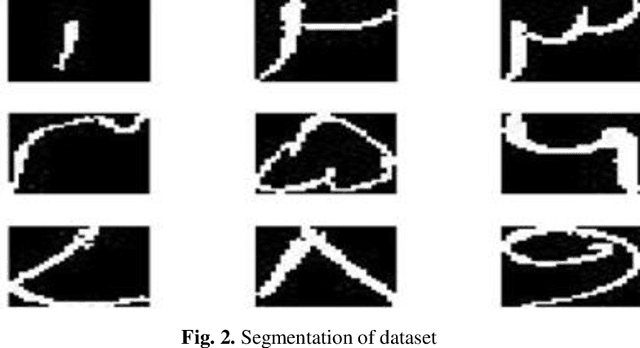
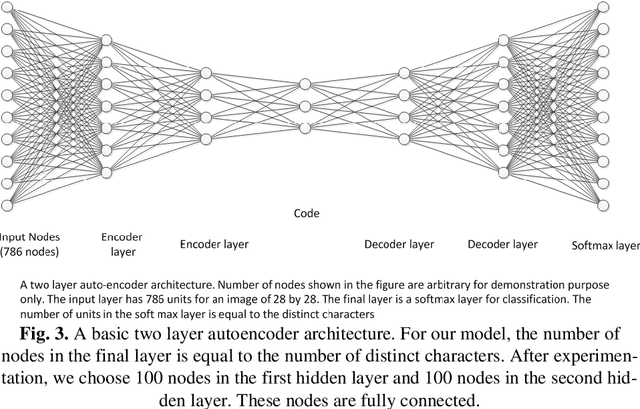
Automatic recognition of Urdu handwritten digits and characters, is a challenging task. It has applications in postal address reading, bank's cheque processing, and digitization and preservation of handwritten manuscripts from old ages. While there exists a significant work for automatic recognition of handwritten English characters and other major languages of the world, the work done for Urdu lan-guage is extremely insufficient. This paper has two goals. Firstly, we introduce a pioneer dataset for handwritten digits and characters of Urdu, containing samples from more than 900 individuals. Secondly, we report results for automatic recog-nition of handwritten digits and characters as achieved by using deep auto-encoder network and convolutional neural network. More specifically, we use a two-layer and a three-layer deep autoencoder network and convolutional neural network and evaluate the two frameworks in terms of recognition accuracy. The proposed framework of deep autoencoder can successfully recognize digits and characters with an accuracy of 97% for digits only, 81% for characters only and 82% for both digits and characters simultaneously. In comparison, the framework of convolutional neural network has accuracy of 96.7% for digits only, 86.5% for characters only and 82.7% for both digits and characters simultaneously. These frameworks can serve as baselines for future research on Urdu handwritten text.