 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Human Behavior on the Block Design Test Through Automated Multi-Level Analysis of Overhead Video
Nov 19, 2018

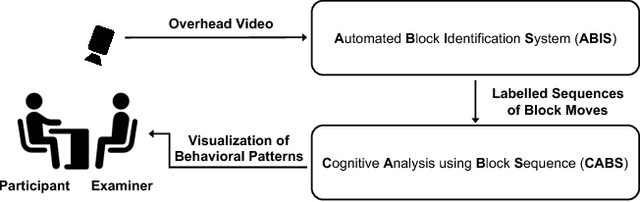
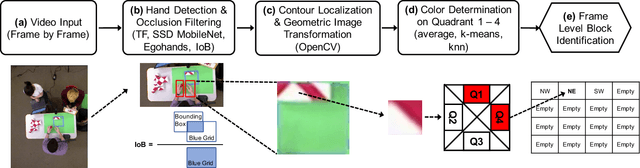
The block design test is a standardized, widely used neuropsychological assessment of visuospatial reasoning that involves a person recreating a series of given designs out of a set of colored blocks. In current testing procedures, an expert neuropsychologist observes a person's accuracy and completion time as well as overall impressions of the person's problem-solving procedures, errors, etc., thus obtaining a holistic though subjective and often qualitative view of the person's cognitive processes. We propose a new framework that combines room sensors and AI techniques to augment the information available to neuropsychologists from block design and similar tabletop assessments. In particular, a ceiling-mounted camera captures an overhead view of the table surface. From this video, we demonstrate how automated classification using machine learning can produce a frame-level description of the state of the block task and the person's actions over the course of each test problem. We also show how a sequence-comparison algorithm can classify one individual's problem-solving strategy relative to a database of simulated strategies, and how these quantitative results can be visualized for use by neuropsychologists.
Seeing Neural Networks Through a Box of Toys: The Toybox Dataset of Visual Object Transformations
Jul 31, 2018


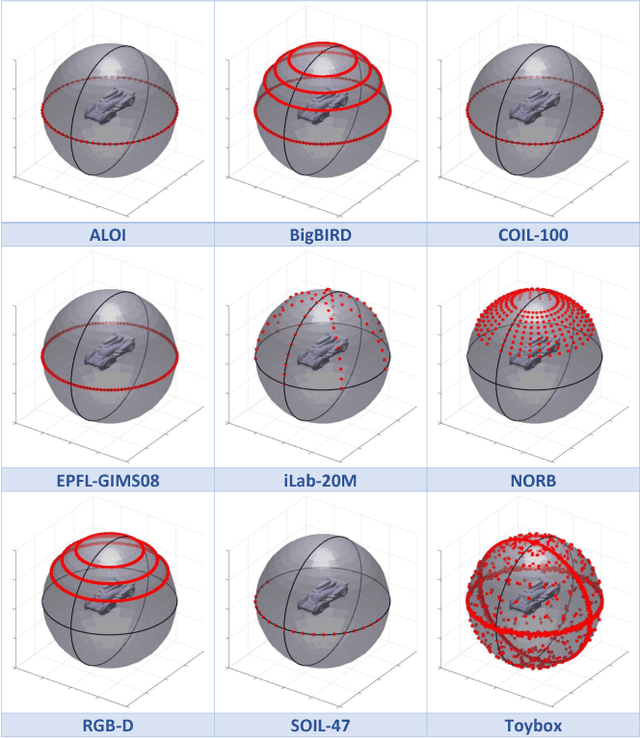
Deep convolutional neural networks (CNNs) have enjoyed tremendous success in computer vision in the past several years, particularly for visual object recognition.However, how CNNs work remains poorly understood, and the training of deep CNNs is still considered more art than science. To better characterize deep CNNs and the training process, we introduce a new video dataset called Toybox. Images in Toybox come from first-person, wearable camera recordings of common household objects and toys being manually manipulated to undergo structured transformations like rotations and translations. We also present results from initial experiments using deep CNNs that begin to examine how different distributions of training data can affect visual object recognition performance, and how visual object concepts are represented within a trained network.