 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Neural Networks Through a Box of Toys: The Toybox Dataset of Visual Object Transformations
Paper and Code
Jul 31, 2018


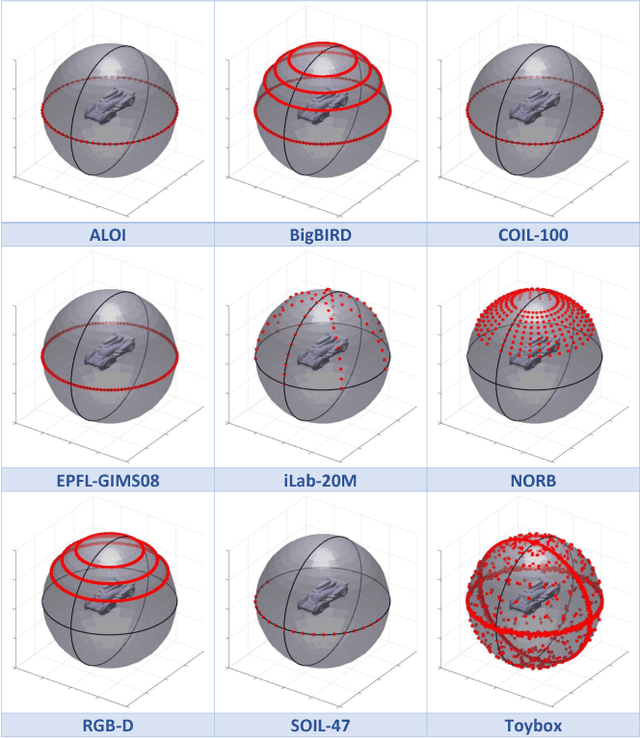
Deep convolutional neural networks (CNNs) have enjoyed tremendous success in computer vision in the past several years, particularly for visual object recognition.However, how CNNs work remains poorly understood, and the training of deep CNNs is still considered more art than science. To better characterize deep CNNs and the training process, we introduce a new video dataset called Toybox. Images in Toybox come from first-person, wearable camera recordings of common household objects and toys being manually manipulated to undergo structured transformations like rotations and translations. We also present results from initial experiments using deep CNNs that begin to examine how different distributions of training data can affect visual object recognition performance, and how visual object concepts are represented within a trained network.