 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety Concerns and Mitigation Approaches Regarding the Use of Deep Learning in Safety-Critical Perception Tasks
Jan 22, 2020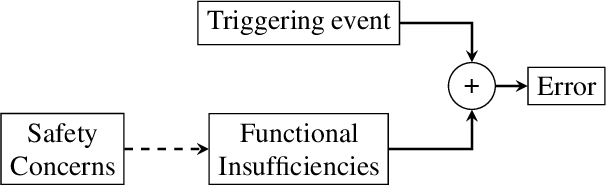
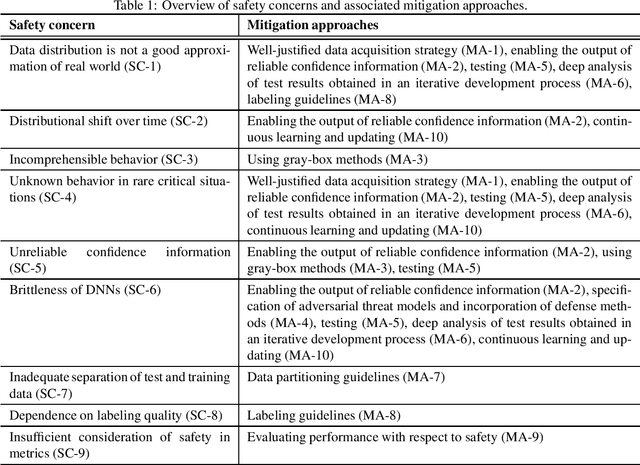
Deep learning methods are widely regarded as indispensable when it comes to designing perception pipelines for autonomous agents such as robots, drones or automated vehicles. The main reasons, however, for deep learning not being used for autonomous agents at large scale already are safety concerns. Deep learning approaches typically exhibit a black-box behavior which makes it hard for them to be evaluated with respect to safety-critical aspects. While there have been some work on safety in deep learning, most papers typically focus on high-level safety concerns. In this work, we seek to dive into the safety concerns of deep learning methods and present a concise enumeration on a deeply technical level. Additionally, we present extensive discussions on possible mitigation methods and give an outlook regarding what mitigation methods are still missing in order to facilitate an argumentation for the safety of a deep learning method.
Expolring Architectures for CNN-Based Word Spotting
Jun 28, 2018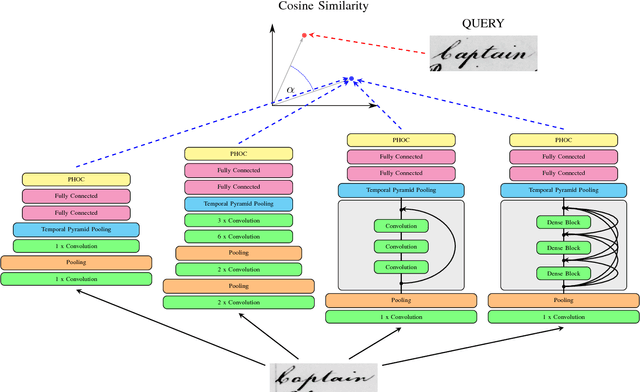

The goal in word spotting is to retrieve parts of document images which are relevant with respect to a certain user-defined query. The recent past has seen attribute-based Convolutional Neural Networks take over this field of research. As is common for other fields of computer vision, the CNNs used for this task are already considerably deep. The question that arises, however, is: How complex does a CNN have to be for word spotting? Are increasingly deeper models giving increasingly bet- ter results or does performance behave asymptotically for these architectures? On the other hand, can similar results be obtained with a much smaller CNN? The goal of this paper is to give an answer to these questions. Therefore, the recently successful TPP- PHOCNet will be compared to a Residual Network, a Densely Connected Convolutional Network and a LeNet architecture empirically. As will be seen in the evaluation, a complex model can be beneficial for word spotting on harder tasks such as the IAM Offline Database but gives no advantage for easier benchmarks such as the George Washington Database.
Weakly Supervised Object Detection with Pointwise Mutual Information
Jan 26, 2018


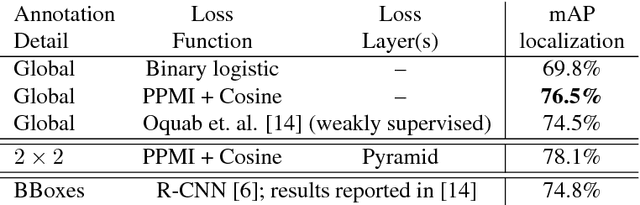
In this work a novel approach for weakly supervised object detection that incorporates pointwise mutual information is presented. A fully convolutional neural network architecture is applied in which the network learns one filter per object class. The resulting feature map indicates the location of objects in an image, yielding an intuitive representation of a class activation map. While traditionally such networks are learned by a softmax or binary logistic regression (sigmoid cross-entropy loss), a learning approach based on a cosine loss is introduced. A pointwise mutual information layer is incorporated in the network in order to project predictions and ground truth presence labels in a non-categorical embedding space. Thus, the cosine loss can be employed in this non-categorical representation. Besides integrating image level annotations, it is shown how to integrate point-wise annotations using a Spatial Pyramid Pooling layer. The approach is evaluated on the VOC2012 dataset for classification, point localization and weakly supervised bounding box localization. It is shown that the combination of pointwise mutual information and a cosine loss eases the learning process and thus improves the accuracy. The integration of coarse point-wise localizations further improves the results at minimal annotation costs.
Learning Deep Representations for Word Spotting Under Weak Supervision
Jan 26, 2018
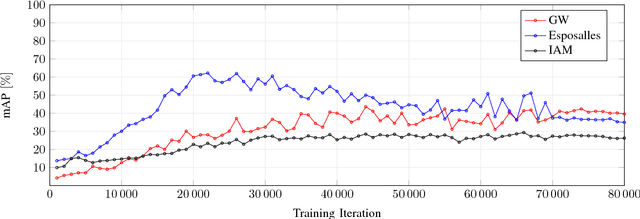

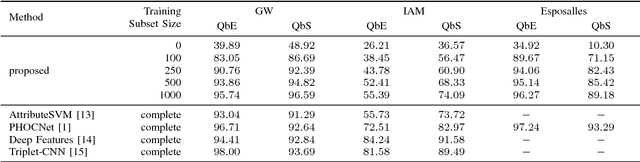
Convolutional Neural Networks have made their mark in various fields of computer vision in recent years. They have achieved state-of-the-art performance in the field of document analysis as well. However, CNNs require a large amount of annotated training data and, hence, great manual effort. In our approach, we introduce a method to drastically reduce the manual annotation effort while retaining the high performance of a CNN for word spotting in handwritten documents. The model is learned with weak supervision using a combination of synthetically generated training data and a small subset of the training partition of the handwritten data set. We show that the network achieves results highly competitive to the state-of-the-art in word spotting with shorter training times and a fraction of the annotation effort.
Attribute CNNs for Word Spotting in Handwritten Documents
Dec 20, 2017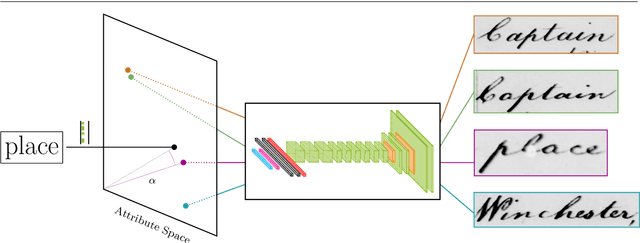

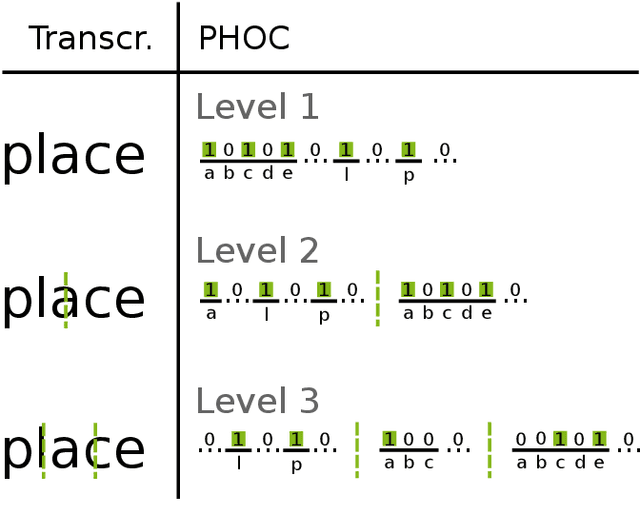
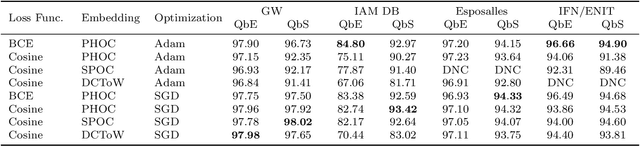
Word spotting has become a field of strong research interest in document image analysis over the last years. Recently, AttributeSVMs were proposed which predict a binary attribute representation. At their time, this influential method defined the state-of-the-art in segmentation-based word spotting. In this work, we present an approach for learning attribute representations with Convolutional Neural Networks (CNNs). By taking a probabilistic perspective on training CNNs, we derive two different loss functions for binary and real-valued word string embeddings. In addition, we propose two different CNN architectures, specifically designed for word spotting. These architectures are able to be trained in an end-to-end fashion. In a number of experiments, we investigate the influence of different word string embeddings and optimization strategies. We show our Attribute CNNs to achieve state-of-the-art results for segmentation-based word spotting on a large variety of data sets.
PHOCNet: A Deep Convolutional Neural Network for Word Spotting in Handwritten Documents
Dec 05, 2017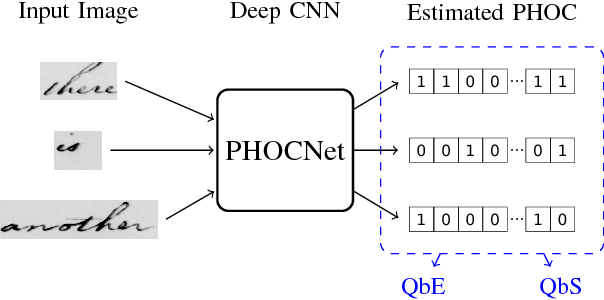
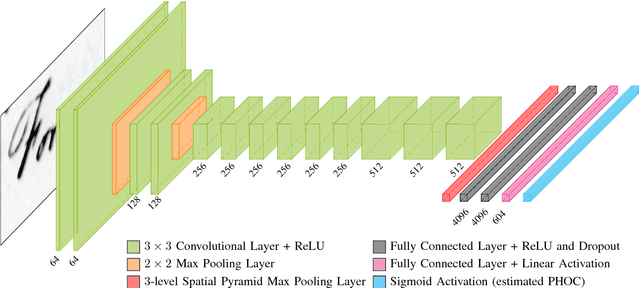

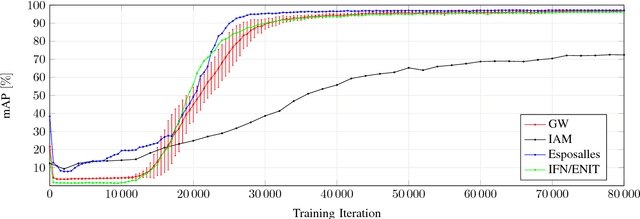
In recent years, deep convolutional neural networks have achieved state of the art performance in various computer vision task such as classification, detection or segmentation. Due to their outstanding performance, CNNs are more and more used in the field of document image analysis as well. In this work, we present a CNN architecture that is trained with the recently proposed PHOC representation. We show empirically that our CNN architecture is able to outperform state of the art results for various word spotting benchmarks while exhibiting short training and test times.
Optimistic and Pessimistic Neural Networks for Scene and Object Recognition
Dec 22, 2016
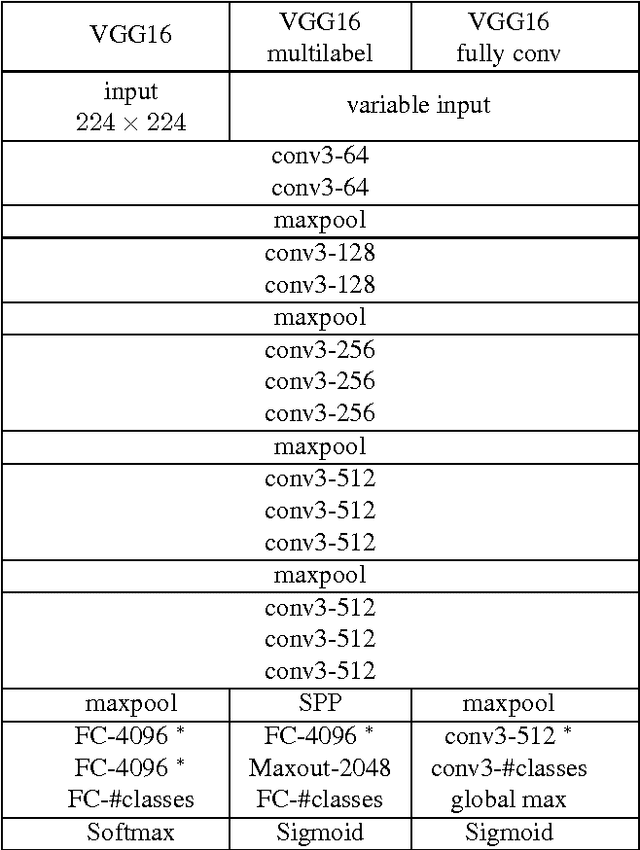
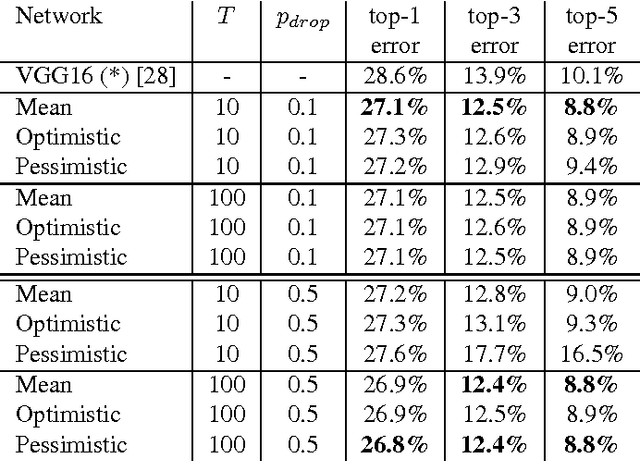
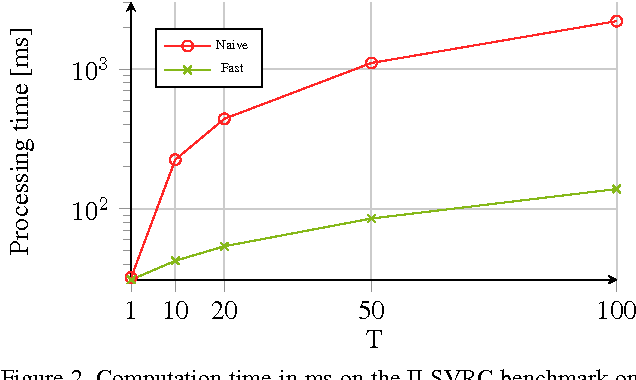
In this paper the application of uncertainty modeling to convolutional neural networks is evaluated. A novel method for adjusting the network's predictions based on uncertainty information is introduced. This allows the network to be either optimistic or pessimistic in its prediction scores. The proposed method builds on the idea of applying dropout at test time and sampling a predictive mean and variance from the network's output. Besides the methodological aspects, implementation details allowing for a fast evaluation are presented. Furthermore, a multilabel network architecture is introduced that strongly benefits from the presented approach. In the evaluation it will be shown that modeling uncertainty allows for improving the performance of a given model purely at test time without any further training steps. The evaluation considers several applications in the field of computer vision, including object classification and detection as well as scene attribute recognition.