 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Object Detection with Pointwise Mutual Information
Jan 26, 2018


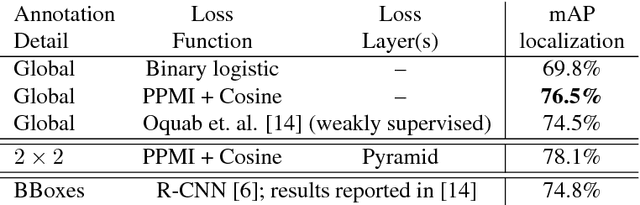
In this work a novel approach for weakly supervised object detection that incorporates pointwise mutual information is presented. A fully convolutional neural network architecture is applied in which the network learns one filter per object class. The resulting feature map indicates the location of objects in an image, yielding an intuitive representation of a class activation map. While traditionally such networks are learned by a softmax or binary logistic regression (sigmoid cross-entropy loss), a learning approach based on a cosine loss is introduced. A pointwise mutual information layer is incorporated in the network in order to project predictions and ground truth presence labels in a non-categorical embedding space. Thus, the cosine loss can be employed in this non-categorical representation. Besides integrating image level annotations, it is shown how to integrate point-wise annotations using a Spatial Pyramid Pooling layer. The approach is evaluated on the VOC2012 dataset for classification, point localization and weakly supervised bounding box localization. It is shown that the combination of pointwise mutual information and a cosine loss eases the learning process and thus improves the accuracy. The integration of coarse point-wise localizations further improves the results at minimal annotation costs.
Neuron Pruning for Compressing Deep Networks using Maxout Architectures
Jul 21, 2017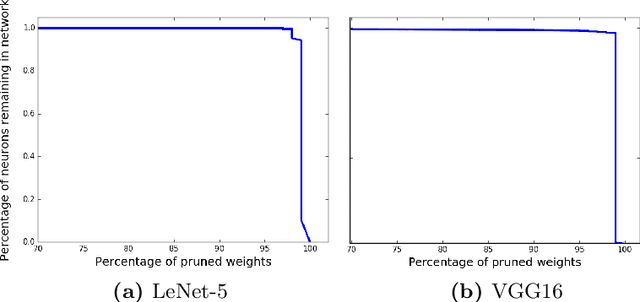
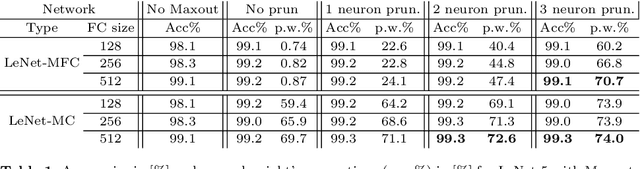
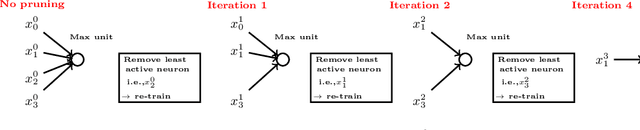
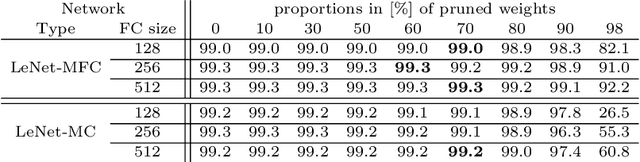
This paper presents an efficient and robust approach for reducing the size of deep neural networks by pruning entire neurons. It exploits maxout units for combining neurons into more complex convex functions and it makes use of a local relevance measurement that ranks neurons according to their activation on the training set for pruning them. Additionally, a parameter reduction comparison between neuron and weight pruning is shown. It will be empirically shown that the proposed neuron pruning reduces the number of parameters dramatically. The evaluation is performed on two tasks, the MNIST handwritten digit recognition and the LFW face verification, using a LeNet-5 and a VGG16 network architecture. The network size is reduced by up to $74\%$ and $61\%$, respectively, without affecting the network's performance. The main advantage of neuron pruning is its direct influence on the size of the network architecture. Furthermore, it will be shown that neuron pruning can be combined with subsequent weight pruning, reducing the size of the LeNet-5 and VGG16 up to $92\%$ and $80\%$ respectively.
Zero-shot object prediction using semantic scene knowledge
Dec 22, 2016



This work focuses on the semantic relations between scenes and objects for visual object recognition. Semantic knowledge can be a powerful source of information especially in scenarios with few or no annotated training samples. These scenarios are referred to as zero-shot or few-shot recognition and often build on visual attributes. Here, instead of relying on various visual attributes, a more direct way is pursued: after recognizing the scene that is depicted in an image, semantic relations between scenes and objects are used for predicting the presence of objects in an unsupervised manner. Most importantly, relations between scenes and objects can easily be obtained from external sources such as large scale text corpora from the web and, therefore, do not require tremendous manual labeling efforts. It will be shown that in cluttered scenes, where visual recognition is difficult, scene knowledge is an important cue for predicting objects.
Optimistic and Pessimistic Neural Networks for Scene and Object Recognition
Dec 22, 2016
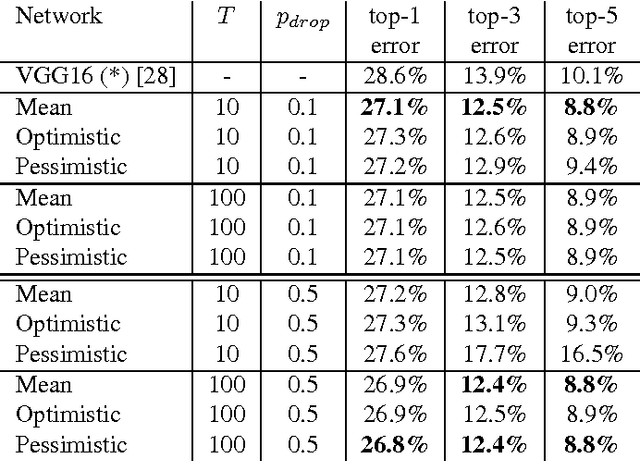
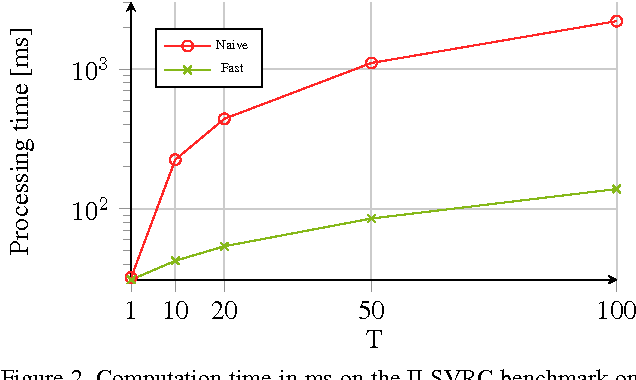
In this paper the application of uncertainty modeling to convolutional neural networks is evaluated. A novel method for adjusting the network's predictions based on uncertainty information is introduced. This allows the network to be either optimistic or pessimistic in its prediction scores. The proposed method builds on the idea of applying dropout at test time and sampling a predictive mean and variance from the network's output. Besides the methodological aspects, implementation details allowing for a fast evaluation are presented. Furthermore, a multilabel network architecture is introduced that strongly benefits from the presented approach. In the evaluation it will be shown that modeling uncertainty allows for improving the performance of a given model purely at test time without any further training steps. The evaluation considers several applications in the field of computer vision, including object classification and detection as well as scene attribute recognition.