 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Acoustical Machine Learning Approach to Determine Abrasive Belt Wear of Wide Belt Sanders
Oct 24, 2022



This paper describes a machine learning approach to determine the abrasive belt wear of wide belt sanders used in industrial processes based on acoustic data, regardless of the sanding process-related parameters, Feed speed, Grit Size, and Type of material. Our approach utilizes Decision Tree, Random Forest, k-nearest Neighbors, and Neural network Classifiers to detect the belt wear from Spectrograms, Mel Spectrograms, MFCC, IMFCC, and LFCC, yielding an accuracy of up to 86.1% on five levels of belt wear. A 96% accuracy could be achieved with different Decision Tree Classifiers specialized in different sanding parameter configurations. The classifiers could also determine with an accuracy of 97% if the machine is currently sanding or is idle and with an accuracy of 98.4% and 98.8% detect the sanding parameters Feed speed and Grit Size. We can show that low-dimensional mappings of high-dimensional features can be used to visualize belt wear and sanding parameters meaningfully.
Nonwords Pronunciation Classification in Language Development Tests for Preschool Children
Jun 17, 2022
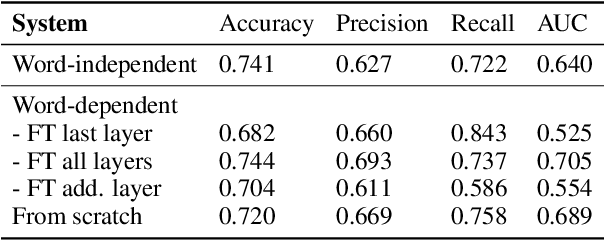
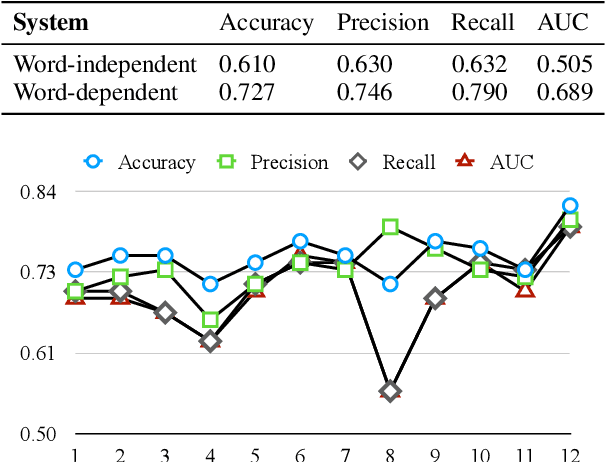

This work aims to automatically evaluate whether the language development of children is age-appropriate. Validated speech and language tests are used for this purpose to test the auditory memory. In this work, the task is to determine whether spoken nonwords have been uttered correctly. We compare different approaches that are motivated to model specific language structures: Low-level features (FFT), speaker embeddings (ECAPA-TDNN), grapheme-motivated embeddings (wav2vec 2.0), and phonetic embeddings in form of senones (ASR acoustic model). Each of the approaches provides input for VGG-like 5-layer CNN classifiers. We also examine the adaptation per nonword. The evaluation of the proposed systems was performed using recordings from different kindergartens of spoken nonwords. ECAPA-TDNN and low-level FFT features do not explicitly model phonetic information; wav2vec2.0 is trained on grapheme labels, our ASR acoustic model features contain (sub-)phonetic information. We found that the more granular the phonetic modeling is, the higher are the achieved recognition rates. The best system trained on ASR acoustic model features with VTLN achieved an accuracy of 89.4% and an area under the ROC (Receiver Operating Characteristic) curve (AUC) of 0.923. This corresponds to an improvement in accuracy of 20.2% and AUC of 0.309 relative compared to the FFT-baseline.