 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelay Variational Inference: A Method for Accelerated Encoderless VI
Oct 26, 2021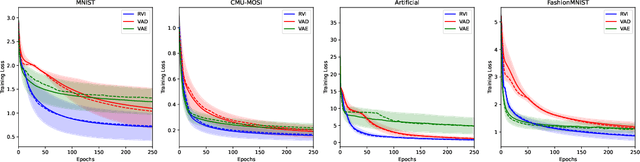
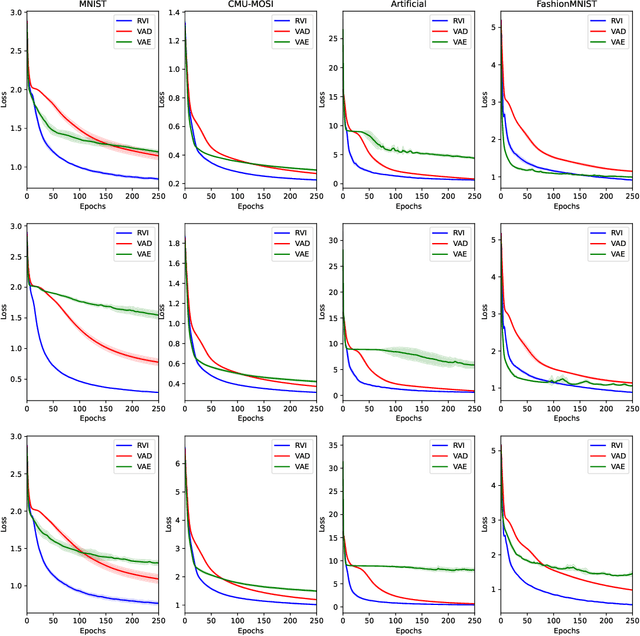
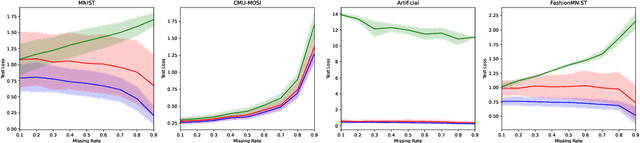
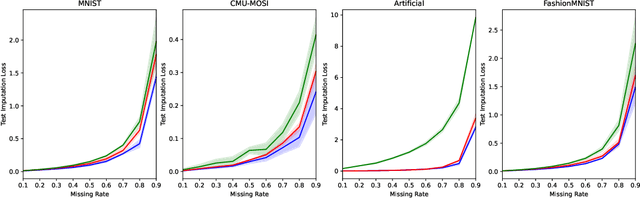
Variational Inference (VI) offers a method for approximating intractable likelihoods. In neural VI, inference of approximate posteriors is commonly done using an encoder. Alternatively, encoderless VI offers a framework for learning generative models from data without encountering suboptimalities caused by amortization via an encoder (e.g. in presence of missing or uncertain data). However, in absence of an encoder, such methods often suffer in convergence due to the slow nature of gradient steps required to learn the approximate posterior parameters. In this paper, we introduce Relay VI (RVI), a framework that dramatically improves both the convergence and performance of encoderless VI. In our experiments over multiple datasets, we study the effectiveness of RVI in terms of convergence speed, loss, representation power and missing data imputation. We find RVI to be a unique tool, often superior in both performance and convergence speed to previously proposed encoderless as well as amortized VI models (e.g. VAE).
StarNet: Gradient-free Training of Deep Generative Models using Determined System of Linear Equations
Jan 03, 2021



In this paper we present an approach for training deep generative models solely based on solving determined systems of linear equations. A network that uses this approach, called a StarNet, has the following desirable properties: 1) training requires no gradient as solution to the system of linear equations is not stochastic, 2) is highly scalable when solving the system of linear equations w.r.t the latent codes, and similarly for the parameters of the model, and 3) it gives desirable least-square bounds for the estimation of latent codes and network parameters within each layer.