Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStarNet: Gradient-free Training of Deep Generative Models using Determined System of Linear Equations
Paper and Code
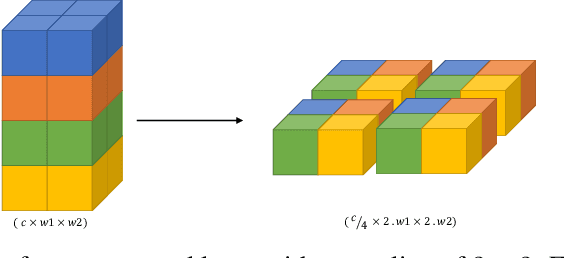



In this paper we present an approach for training deep generative models solely based on solving determined systems of linear equations. A network that uses this approach, called a StarNet, has the following desirable properties: 1) training requires no gradient as solution to the system of linear equations is not stochastic, 2) is highly scalable when solving the system of linear equations w.r.t the latent codes, and similarly for the parameters of the model, and 3) it gives desirable least-square bounds for the estimation of latent codes and network parameters within each layer.
* Work in progress at CMU
View paper on