 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHallucinate, Ground, Repeat: A Framework for Generalized Visual Relationship Detection
Jun 06, 2025



Understanding relationships between objects is central to visual intelligence, with applications in embodied AI, assistive systems, and scene understanding. Yet, most visual relationship detection (VRD) models rely on a fixed predicate set, limiting their generalization to novel interactions. A key challenge is the inability to visually ground semantically plausible, but unannotated, relationships hypothesized from external knowledge. This work introduces an iterative visual grounding framework that leverages large language models (LLMs) as structured relational priors. Inspired by expectation-maximization (EM), our method alternates between generating candidate scene graphs from detected objects using an LLM (expectation) and training a visual model to align these hypotheses with perceptual evidence (maximization). This process bootstraps relational understanding beyond annotated data and enables generalization to unseen predicates. Additionally, we introduce a new benchmark for open-world VRD on Visual Genome with 21 held-out predicates and evaluate under three settings: seen, unseen, and mixed. Our model outperforms LLM-only, few-shot, and debiased baselines, achieving mean recall (mR@50) of 15.9, 13.1, and 11.7 on predicate classification on these three sets. These results highlight the promise of grounded LLM priors for scalable open-world visual understanding.
A Probabilistic Jump-Diffusion Framework for Open-World Egocentric Activity Recognition
May 28, 2025



Open-world egocentric activity recognition poses a fundamental challenge due to its unconstrained nature, requiring models to infer unseen activities from an expansive, partially observed search space. We introduce ProbRes, a Probabilistic Residual search framework based on jump-diffusion that efficiently navigates this space by balancing prior-guided exploration with likelihood-driven exploitation. Our approach integrates structured commonsense priors to construct a semantically coherent search space, adaptively refines predictions using Vision-Language Models (VLMs) and employs a stochastic search mechanism to locate high-likelihood activity labels while minimizing exhaustive enumeration efficiently. We systematically evaluate ProbRes across multiple openness levels (L0--L3), demonstrating its adaptability to increasing search space complexity. In addition to achieving state-of-the-art performance on benchmark datasets (GTEA Gaze, GTEA Gaze+, EPIC-Kitchens, and Charades-Ego), we establish a clear taxonomy for open-world recognition, delineating the challenges and methodological advancements necessary for egocentric activity understanding.
ProbRes: Probabilistic Jump Diffusion for Open-World Egocentric Activity Recognition
Apr 04, 2025



Open-world egocentric activity recognition poses a fundamental challenge due to its unconstrained nature, requiring models to infer unseen activities from an expansive, partially observed search space. We introduce ProbRes, a Probabilistic Residual search framework based on jump-diffusion that efficiently navigates this space by balancing prior-guided exploration with likelihood-driven exploitation. Our approach integrates structured commonsense priors to construct a semantically coherent search space, adaptively refines predictions using Vision-Language Models (VLMs) and employs a stochastic search mechanism to locate high-likelihood activity labels while minimizing exhaustive enumeration efficiently. We systematically evaluate ProbRes across multiple openness levels (L0 - L3), demonstrating its adaptability to increasing search space complexity. In addition to achieving state-of-the-art performance on benchmark datasets (GTEA Gaze, GTEA Gaze+, EPIC-Kitchens, and Charades-Ego), we establish a clear taxonomy for open-world recognition, delineating the challenges and methodological advancements necessary for egocentric activity understanding. Our results highlight the importance of structured search strategies, paving the way for scalable and efficient open-world activity recognition.
ALGO: Object-Grounded Visual Commonsense Reasoning for Open-World Egocentric Action Recognition
Jun 09, 2024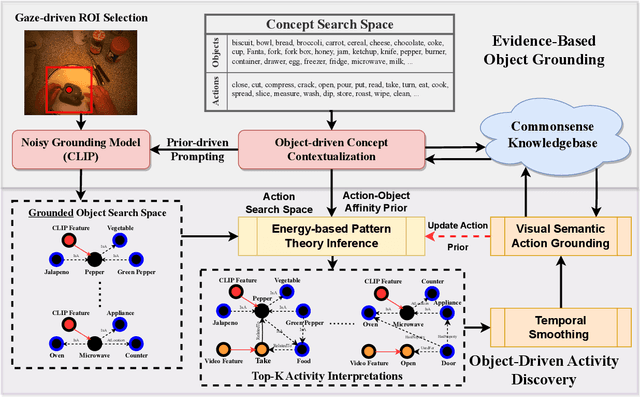
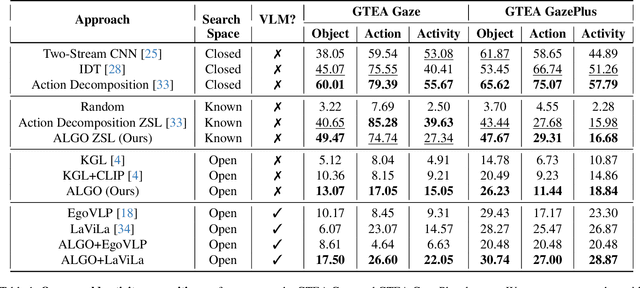
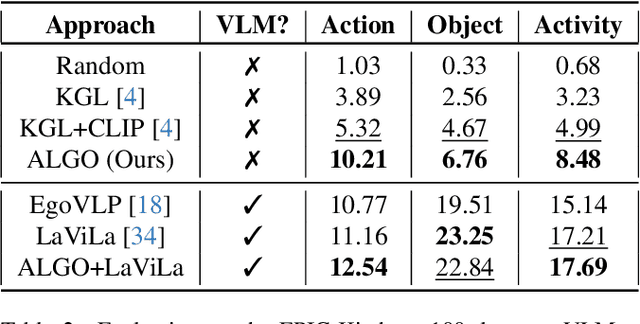
Learning to infer labels in an open world, i.e., in an environment where the target "labels" are unknown, is an important characteristic for achieving autonomy. Foundation models pre-trained on enormous amounts of data have shown remarkable generalization skills through prompting, particularly in zero-shot inference. However, their performance is restricted to the correctness of the target label's search space. In an open world, this target search space can be unknown or exceptionally large, which severely restricts the performance of such models. To tackle this challenging problem, we propose a neuro-symbolic framework called ALGO - Action Learning with Grounded Object recognition that uses symbolic knowledge stored in large-scale knowledge bases to infer activities in egocentric videos with limited supervision using two steps. First, we propose a neuro-symbolic prompting approach that uses object-centric vision-language models as a noisy oracle to ground objects in the video through evidence-based reasoning. Second, driven by prior commonsense knowledge, we discover plausible activities through an energy-based symbolic pattern theory framework and learn to ground knowledge-based action (verb) concepts in the video. Extensive experiments on four publicly available datasets (EPIC-Kitchens, GTEA Gaze, GTEA Gaze Plus) demonstrate its performance on open-world activity inference.
Discovering Novel Actions in an Open World with Object-Grounded Visual Commonsense Reasoning
May 26, 2023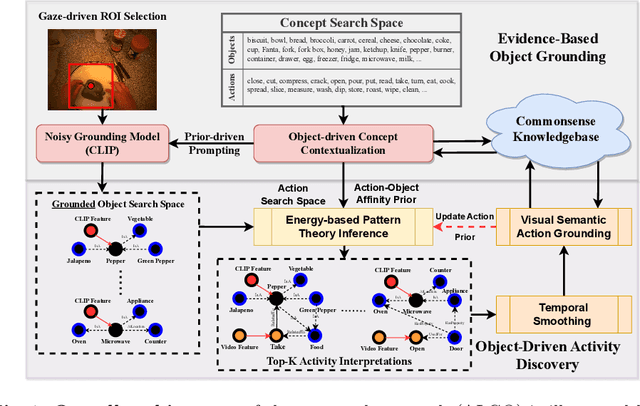
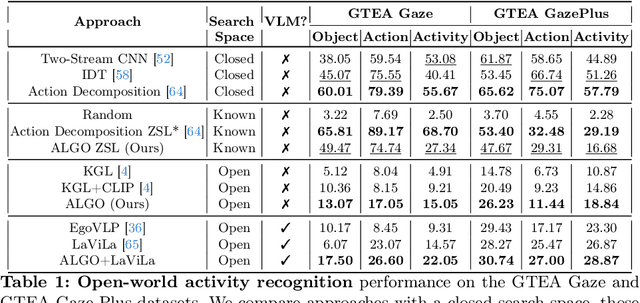
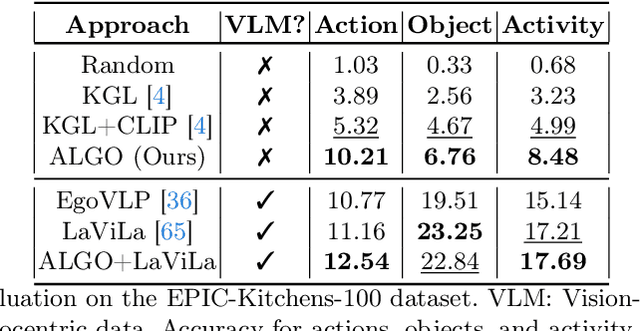
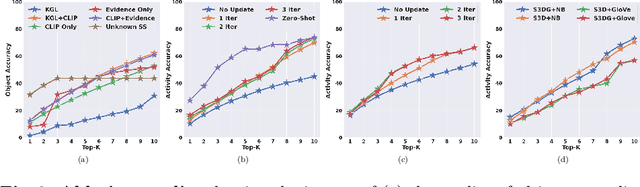
Learning to infer labels in an open world, i.e., in an environment where the target ``labels'' are unknown, is an important characteristic for achieving autonomy. Foundation models pre-trained on enormous amounts of data have shown remarkable generalization skills through prompting, particularly in zero-shot inference. However, their performance is restricted to the correctness of the target label's search space. In an open world where these labels are unknown, the search space can be exceptionally large. It can require reasoning over several combinations of elementary concepts to arrive at an inference, which severely restricts the performance of such models. To tackle this challenging problem, we propose a neuro-symbolic framework called ALGO - novel Action Learning with Grounded Object recognition that can use symbolic knowledge stored in large-scale knowledge bases to infer activities (verb-noun combinations) in egocentric videos with limited supervision using two steps. First, we propose a novel neuro-symbolic prompting approach that uses object-centric vision-language foundation models as a noisy oracle to ground objects in the video through evidence-based reasoning. Second, driven by prior commonsense knowledge, we discover plausible activities through an energy-based symbolic pattern theory framework and learn to ground knowledge-based action (verb) concepts in the video. Extensive experiments on two publicly available datasets (GTEA Gaze and GTEA Gaze Plus) demonstrate its performance on open-world activity inference and its generalization to unseen actions in an unknown search space. We show that ALGO can be extended to zero-shot settings and demonstrate its competitive performance to multimodal foundation models.
Iterative Scene Graph Generation with Generative Transformers
Nov 30, 2022



Scene graphs provide a rich, structured representation of a scene by encoding the entities (objects) and their spatial relationships in a graphical format. This representation has proven useful in several tasks, such as question answering, captioning, and even object detection, to name a few. Current approaches take a generation-by-classification approach where the scene graph is generated through labeling of all possible edges between objects in a scene, which adds computational overhead to the approach. This work introduces a generative transformer-based approach to generating scene graphs beyond link prediction. Using two transformer-based components, we first sample a possible scene graph structure from detected objects and their visual features. We then perform predicate classification on the sampled edges to generate the final scene graph. This approach allows us to efficiently generate scene graphs from images with minimal inference overhead. Extensive experiments on the Visual Genome dataset demonstrate the efficiency of the proposed approach. Without bells and whistles, we obtain, on average, 20.7% mean recall (mR@100) across different settings for scene graph generation (SGG), outperforming state-of-the-art SGG approaches while offering competitive performance to unbiased SGG approaches.
Knowledge Guided Learning: Towards Open Domain Egocentric Action Recognition with Zero Supervision
Sep 16, 2020



Advances in deep learning have enabled the development of models that have exhibited a remarkable tendency to recognize and even localize actions in videos. However, they tend to experience errors when faced with scenes or examples beyond their initial training environment. Hence, they fail to adapt to new domains without significant retraining with large amounts of annotated data. Current algorithms are trained in an inductive learning environment where they use data-driven models to learn associations between input observations with a fixed set of known classes. In this paper, we propose to overcome these limitations by moving to an open world setting by decoupling the ideas of recognition and reasoning. Building upon the compositional representation offered by Grenander's Pattern Theory formalism, we show that attention and commonsense knowledge can be used to enable the self-supervised discovery of novel actions in egocentric videos in an open-world setting, a considerably more difficult task than zero-shot learning and (un)supervised domain adaptation tasks where target domain data (both labeled and unlabeled) are available during training. We show that our approach can be used to infer and learn novel classes for open vocabulary classification in egocentric videos and novel object detection with zero supervision. Extensive experiments show that it performs competitively with fully supervised baselines on publicly available datasets under open-world conditions. This is one of the first works to address the problem of open-world action recognition in egocentric videos with zero human supervision to the best of our knowledge.