 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Novel Actions in an Open World with Object-Grounded Visual Commonsense Reasoning
Paper and Code
May 26, 2023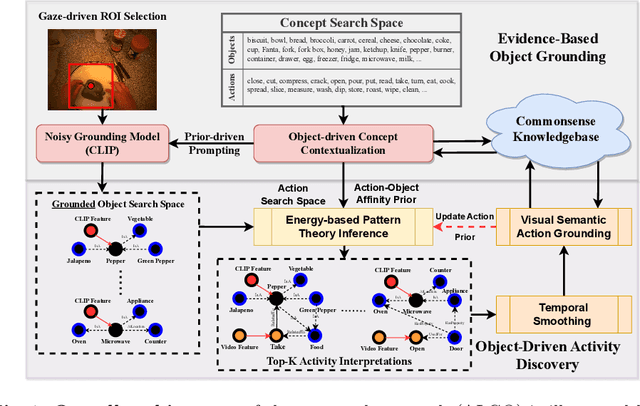
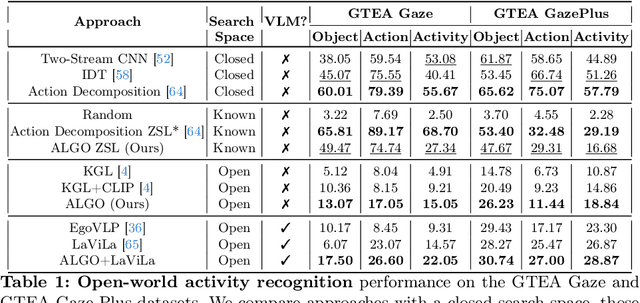
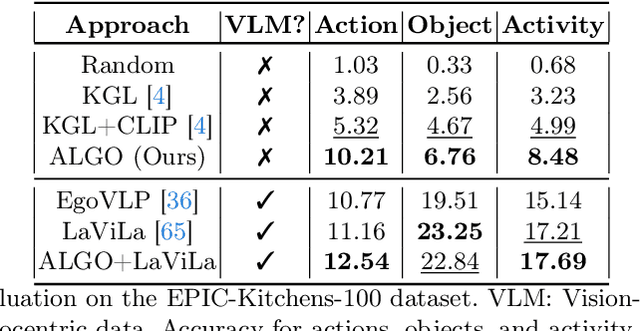
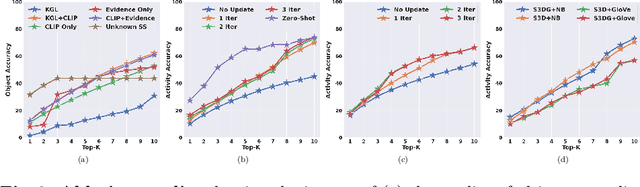
Learning to infer labels in an open world, i.e., in an environment where the target ``labels'' are unknown, is an important characteristic for achieving autonomy. Foundation models pre-trained on enormous amounts of data have shown remarkable generalization skills through prompting, particularly in zero-shot inference. However, their performance is restricted to the correctness of the target label's search space. In an open world where these labels are unknown, the search space can be exceptionally large. It can require reasoning over several combinations of elementary concepts to arrive at an inference, which severely restricts the performance of such models. To tackle this challenging problem, we propose a neuro-symbolic framework called ALGO - novel Action Learning with Grounded Object recognition that can use symbolic knowledge stored in large-scale knowledge bases to infer activities (verb-noun combinations) in egocentric videos with limited supervision using two steps. First, we propose a novel neuro-symbolic prompting approach that uses object-centric vision-language foundation models as a noisy oracle to ground objects in the video through evidence-based reasoning. Second, driven by prior commonsense knowledge, we discover plausible activities through an energy-based symbolic pattern theory framework and learn to ground knowledge-based action (verb) concepts in the video. Extensive experiments on two publicly available datasets (GTEA Gaze and GTEA Gaze Plus) demonstrate its performance on open-world activity inference and its generalization to unseen actions in an unknown search space. We show that ALGO can be extended to zero-shot settings and demonstrate its competitive performance to multimodal foundation models.