 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDavid and Goliath: An Empirical Evaluation of Attacks and Defenses for QNNs at the Deep Edge
Apr 08, 2024



ML is shifting from the cloud to the edge. Edge computing reduces the surface exposing private data and enables reliable throughput guarantees in real-time applications. Of the panoply of devices deployed at the edge, resource-constrained MCUs, e.g., Arm Cortex-M, are more prevalent, orders of magnitude cheaper, and less power-hungry than application processors or GPUs. Thus, enabling intelligence at the deep edge is the zeitgeist, with researchers focusing on unveiling novel approaches to deploy ANNs on these constrained devices. Quantization is a well-established technique that has proved effective in enabling the deployment of neural networks on MCUs; however, it is still an open question to understand the robustness of QNNs in the face of adversarial examples. To fill this gap, we empirically evaluate the effectiveness of attacks and defenses from (full-precision) ANNs on (constrained) QNNs. Our evaluation includes three QNNs targeting TinyML applications, ten attacks, and six defenses. With this study, we draw a set of interesting findings. First, quantization increases the point distance to the decision boundary and leads the gradient estimated by some attacks to explode or vanish. Second, quantization can act as a noise attenuator or amplifier, depending on the noise magnitude, and causes gradient misalignment. Regarding adversarial defenses, we conclude that input pre-processing defenses show impressive results on small perturbations; however, they fall short as the perturbation increases. At the same time, train-based defenses increase the average point distance to the decision boundary, which holds after quantization. However, we argue that train-based defenses still need to smooth the quantization-shift and gradient misalignment phenomenons to counteract adversarial example transferability to QNNs. All artifacts are open-sourced to enable independent validation of results.
A Heterogeneous RISC-V based SoC for Secure Nano-UAV Navigation
Jan 07, 2024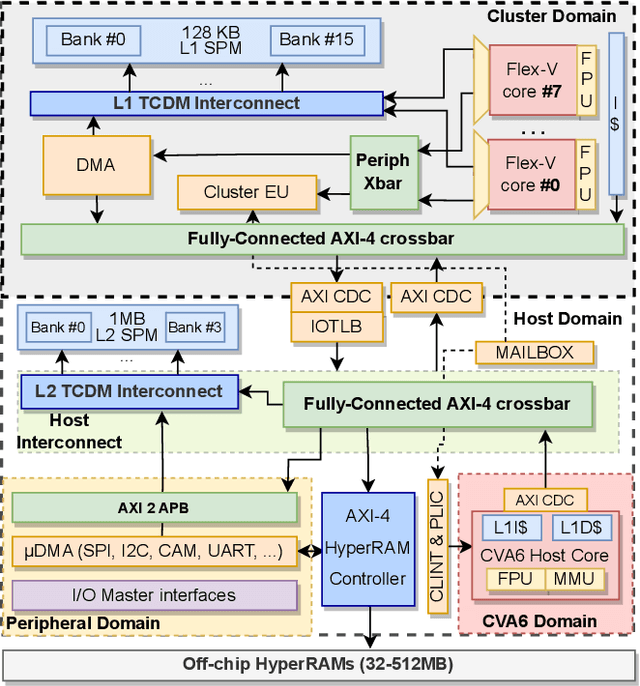
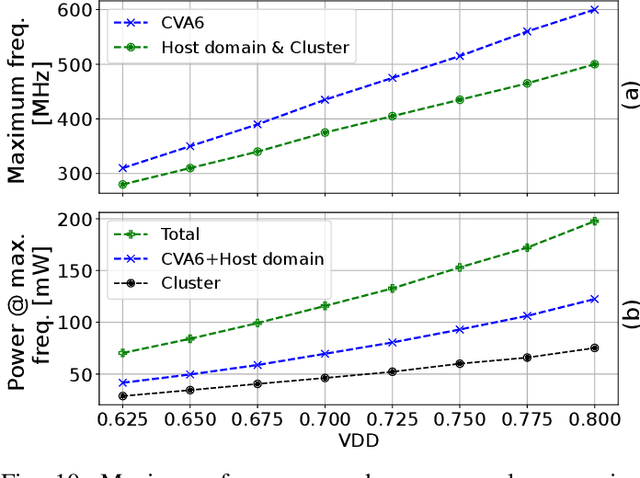
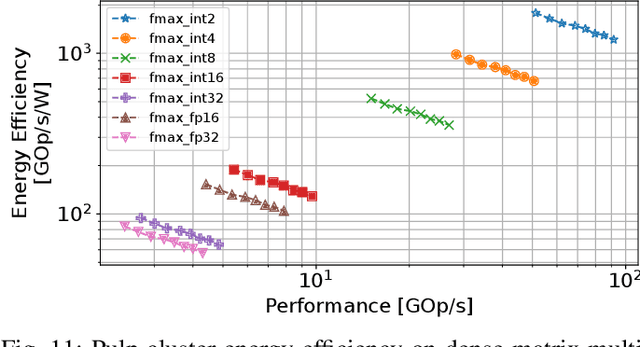
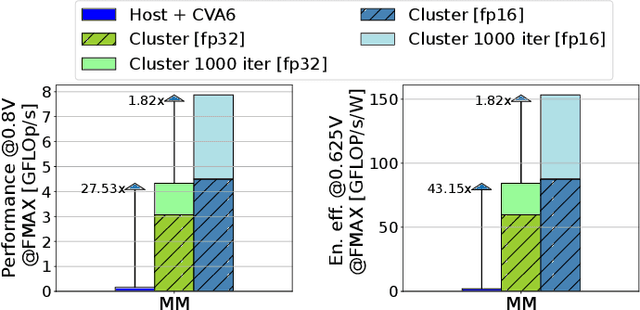
The rapid advancement of energy-efficient parallel ultra-low-power (ULP) ucontrollers units (MCUs) is enabling the development of autonomous nano-sized unmanned aerial vehicles (nano-UAVs). These sub-10cm drones represent the next generation of unobtrusive robotic helpers and ubiquitous smart sensors. However, nano-UAVs face significant power and payload constraints while requiring advanced computing capabilities akin to standard drones, including real-time Machine Learning (ML) performance and the safe co-existence of general-purpose and real-time OSs. Although some advanced parallel ULP MCUs offer the necessary ML computing capabilities within the prescribed power limits, they rely on small main memories (<1MB) and ucontroller-class CPUs with no virtualization or security features, and hence only support simple bare-metal runtimes. In this work, we present Shaheen, a 9mm2 200mW SoC implemented in 22nm FDX technology. Differently from state-of-the-art MCUs, Shaheen integrates a Linux-capable RV64 core, compliant with the v1.0 ratified Hypervisor extension and equipped with timing channel protection, along with a low-cost and low-power memory controller exposing up to 512MB of off-chip low-cost low-power HyperRAM directly to the CPU. At the same time, it integrates a fully programmable energy- and area-efficient multi-core cluster of RV32 cores optimized for general-purpose DSP as well as reduced- and mixed-precision ML. To the best of the authors' knowledge, it is the first silicon prototype of a ULP SoC coupling the RV64 and RV32 cores in a heterogeneous host+accelerator architecture fully based on the RISC-V ISA. We demonstrate the capabilities of the proposed SoC on a wide range of benchmarks relevant to nano-UAV applications. The cluster can deliver up to 90GOp/s and up to 1.8TOp/s/W on 2-bit integer kernels and up to 7.9GFLOp/s and up to 150GFLOp/s/W on 16-bit FP kernels.
Shifting Capsule Networks from the Cloud to the Deep Edge
Oct 06, 2021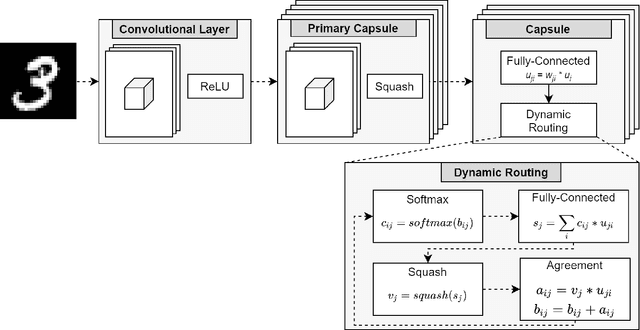
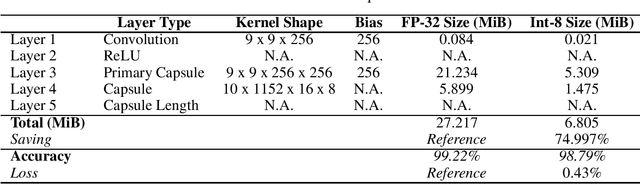
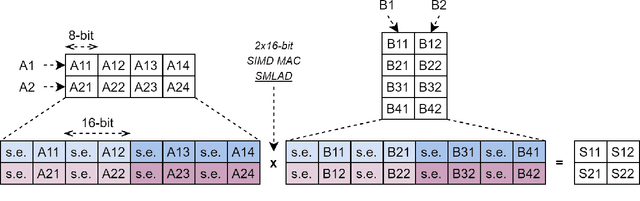

Capsule networks (CapsNets) are an emerging trend in image processing. In contrast to a convolutional neural network, CapsNets are not vulnerable to object deformation, as the relative spatial information of the objects is preserved across the network. However, their complexity is mainly related with the capsule structure and the dynamic routing mechanism, which makes it almost unreasonable to deploy a CapsNet, in its original form, in a resource-constrained device powered by a small microcontroller (MCU). In an era where intelligence is rapidly shifting from the cloud to the edge, this high complexity imposes serious challenges to the adoption of CapsNets at the very edge. To tackle this issue, we present an API for the execution of quantized CapsNets in Cortex-M and RISC-V MCUs. Our software kernels extend the Arm CMSIS-NN and RISC-V PULP-NN, to support capsule operations with 8-bit integers as operands. Along with it, we propose a framework to perform post training quantization of a CapsNet. Results show a reduction in memory footprint of almost 75%, with a maximum accuracy loss of 1%. In terms of throughput, our software kernels for the Arm Cortex-M are, at least, 5.70x faster than a pre-quantized CapsNet running on an NVIDIA GTX 980 Ti graphics card. For RISC-V, the throughout gain increases to 26.28x and 56.91x for a single- and octa-core configuration, respectively.