 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignal Recovery Using a Spiked Mixture Model
Jan 03, 2025



We introduce the spiked mixture model (SMM) to address the problem of estimating a set of signals from many randomly scaled and noisy observations. Subsequently, we design a novel expectation-maximization (EM) algorithm to recover all parameters of the SMM. Numerical experiments show that in low signal-to-noise ratio regimes, and for data types where the SMM is relevant, SMM surpasses the more traditional Gaussian mixture model (GMM) in terms of signal recovery performance. The broad relevance of the SMM and its corresponding EM recovery algorithm is demonstrated by applying the technique to different data types. The first case study is a biomedical research application, utilizing an imaging mass spectrometry dataset to explore the molecular content of a rat brain tissue section at micrometer scale. The second case study demonstrates SMM performance in a computer vision application, segmenting a hyperspectral imaging dataset into underlying patterns. While the measurement modalities differ substantially, in both case studies SMM is shown to recover signals that were missed by traditional methods such as k-means clustering and GMM.
Structured Sensing Matrix Design for In-sector Compressed mmWave Channel Estimation
May 23, 2022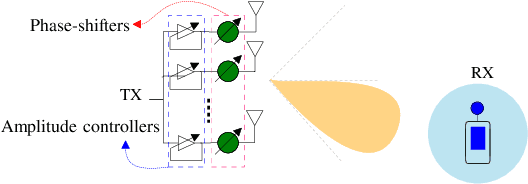
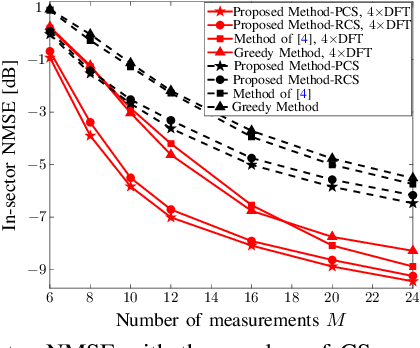
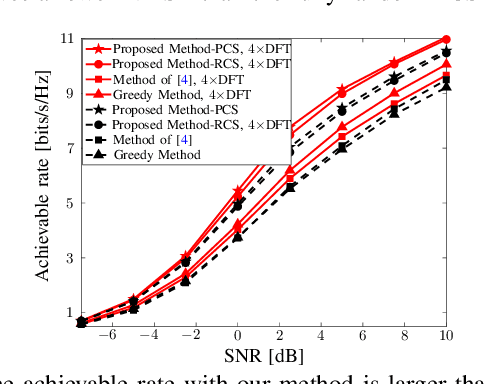
Fast millimeter wave (mmWave) channel estimation techniques based on compressed sensing (CS) suffer from low signal-to-noise ratio (SNR) in the channel measurements, due to the use of wide beams. To address this problem, we develop an in-sector CS-based mmWave channel estimation technique that focuses energy on a sector in the angle domain. Specifically, we construct a new class of structured CS matrices to estimate the channel within the sector of interest. To this end, we first determine an optimal sampling pattern when the number of measurements is equal to the sector dimension and then use its subsampled version in the sub-Nyquist regime. Our approach results in low aliasing artifacts in the sector of interest and better channel estimates than benchmark algorithms.
Efficient Training of Volterra Series-Based Pre-distortion Filter Using Neural Networks
Dec 13, 2021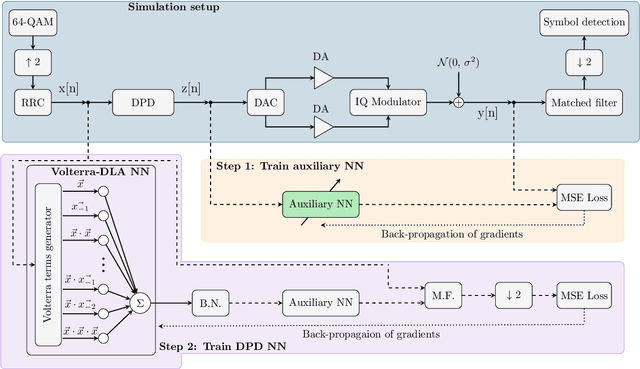
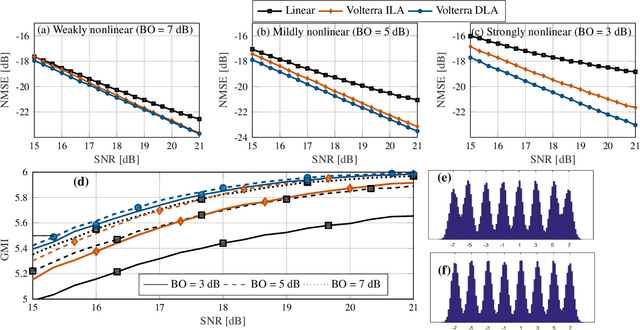
We present a simple, efficient "direct learning" approach to train Volterra series-based digital pre-distortion filters using neural networks. We show its superior performance over conventional training methods using a 64-QAM 64-GBaud simulated transmitter with varying transmitter nonlinearity and noisy conditions.
Online Optimization with Costly and Noisy Measurements using Random Fourier Expansions
Sep 29, 2016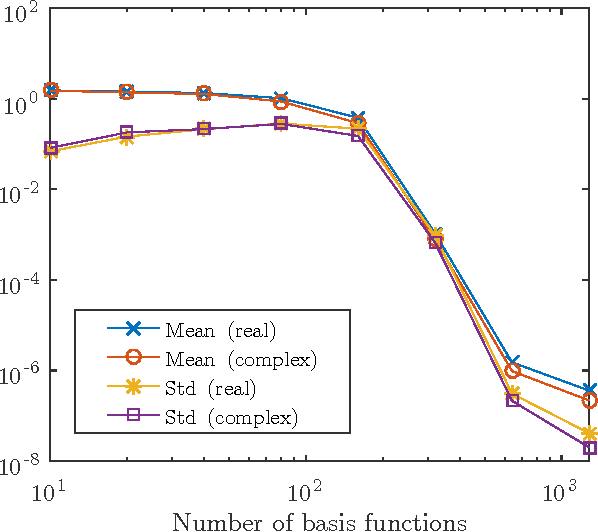
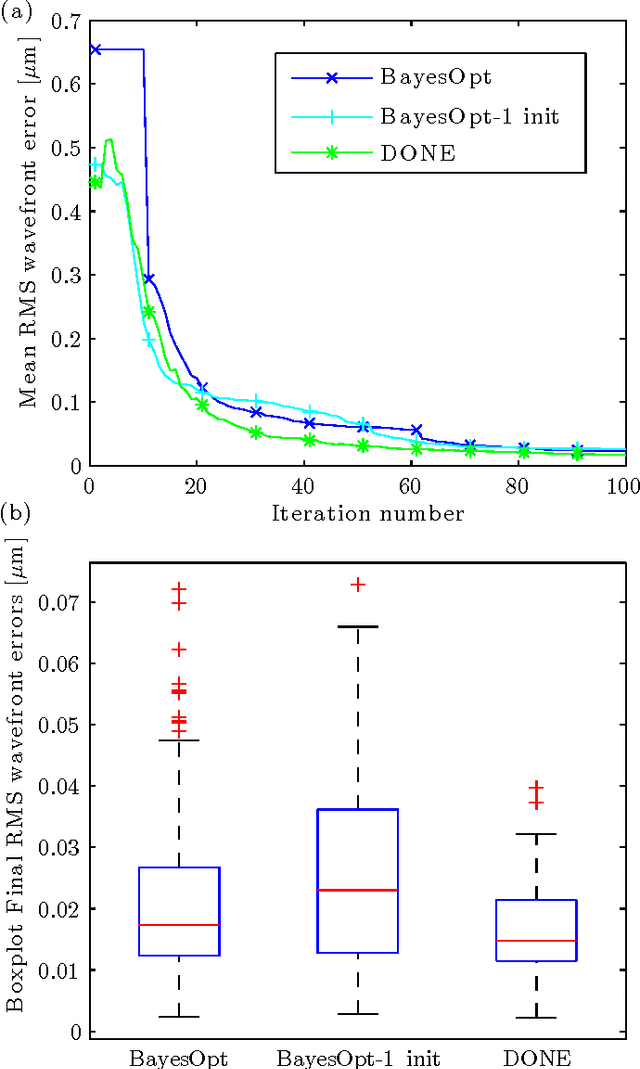
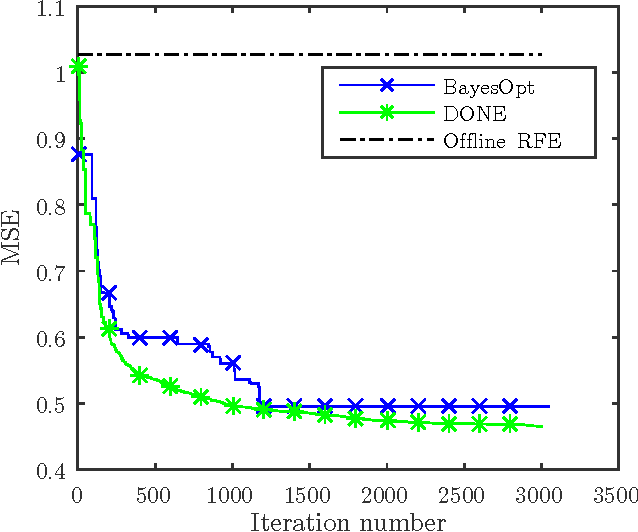
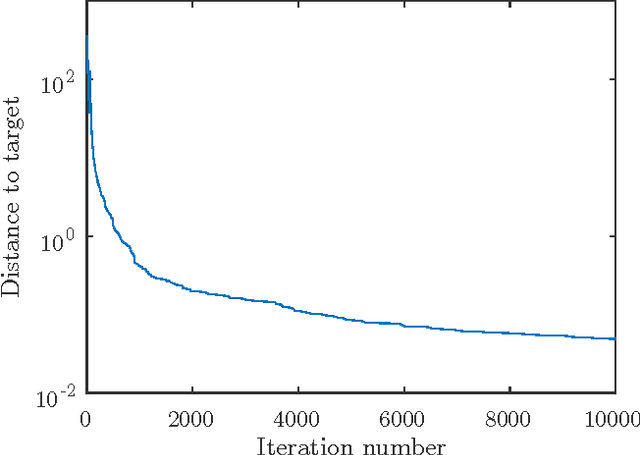
This paper analyzes DONE, an online optimization algorithm that iteratively minimizes an unknown function based on costly and noisy measurements. The algorithm maintains a surrogate of the unknown function in the form of a random Fourier expansion (RFE). The surrogate is updated whenever a new measurement is available, and then used to determine the next measurement point. The algorithm is comparable to Bayesian optimization algorithms, but its computational complexity per iteration does not depend on the number of measurements. We derive several theoretical results that provide insight on how the hyper-parameters of the algorithm should be chosen. The algorithm is compared to a Bayesian optimization algorithm for a benchmark problem and three applications, namely, optical coherence tomography, optical beam-forming network tuning, and robot arm control. It is found that the DONE algorithm is significantly faster than Bayesian optimization in the discussed problems, while achieving a similar or better performance.