 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Deep Latent Space Particle Filter for Real-Time Data Assimilation with Uncertainty Quantification
Jun 04, 2024In Data Assimilation, observations are fused with simulations to obtain an accurate estimate of the state and parameters for a given physical system. Combining data with a model, however, while accurately estimating uncertainty, is computationally expensive and infeasible to run in real-time for complex systems. Here, we present a novel particle filter methodology, the Deep Latent Space Particle filter or D-LSPF, that uses neural network-based surrogate models to overcome this computational challenge. The D-LSPF enables filtering in the low-dimensional latent space obtained using Wasserstein AEs with modified vision transformer layers for dimensionality reduction and transformers for parameterized latent space time stepping. As we demonstrate on three test cases, including leak localization in multi-phase pipe flow and seabed identification for fully nonlinear water waves, the D-LSPF runs orders of magnitude faster than a high-fidelity particle filter and 3-5 times faster than alternative methods while being up to an order of magnitude more accurate. The D-LSPF thus enables real-time data assimilation with uncertainty quantification for physical systems.
Masked Image Modeling as a Framework for Self-Supervised Learning across Eye Movements
Apr 12, 2024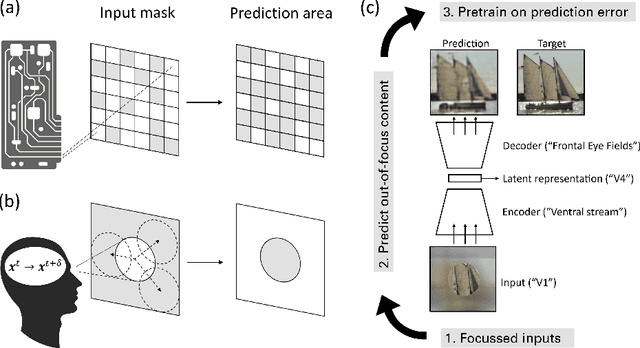


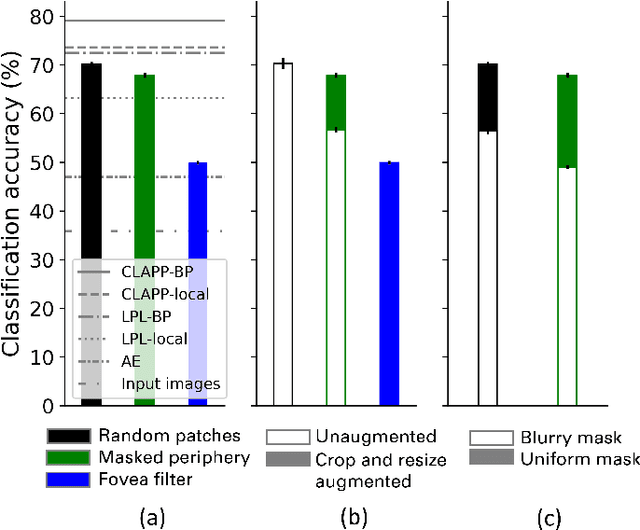
To make sense of their surroundings, intelligent systems must transform complex sensory inputs to structured codes that are reduced to task-relevant information such as object category. Biological agents achieve this in a largely autonomous manner, presumably via self-\allowbreak super-\allowbreak vised learning. Whereas previous attempts to model the underlying mechanisms were largely discriminative in nature, there is ample evidence that the brain employs a generative model of the world. Here, we propose that eye movements, in combination with the focused nature of primate vision, constitute a generative, self-supervised task of predicting and revealing visual information. We construct a proof-of-principle model starting from the framework of masked image modeling (MIM), a common approach in deep representation learning. To do so, we analyze how core components of MIM such as masking technique and data augmentation influence the formation of category-specific representations. This allows us not only to better understand the principles behind MIM, but to then reassemble a MIM more in line with the focused nature of biological perception. From a theoretical angle, we find that MIM disentangles neurons in latent space, a property that has been suggested to structure visual representations in primates, without explicit regulation. Together with previous findings of invariance learning, this highlights an interesting connection of MIM to latent regularization approaches for self-supervised learning. The source code is available under https://github.com/RobinWeiler/FocusMIM
Effective and Efficient Computation with Multiple-timescale Spiking Recurrent Neural Networks
Jun 16, 2020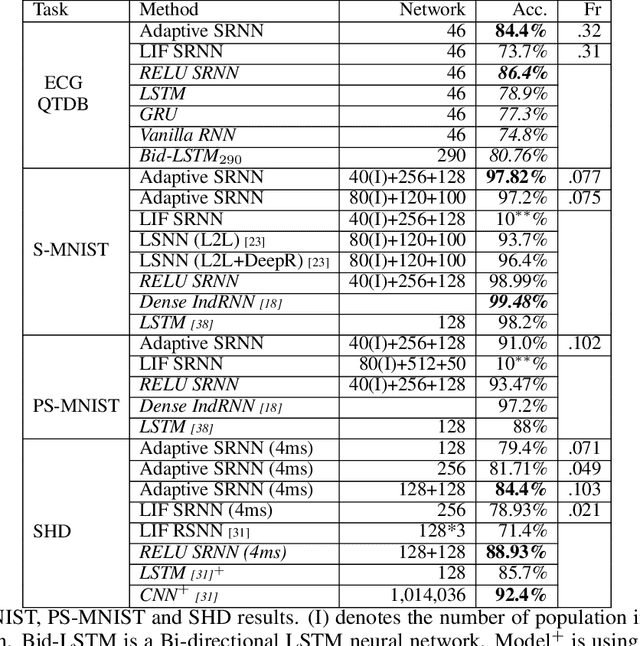


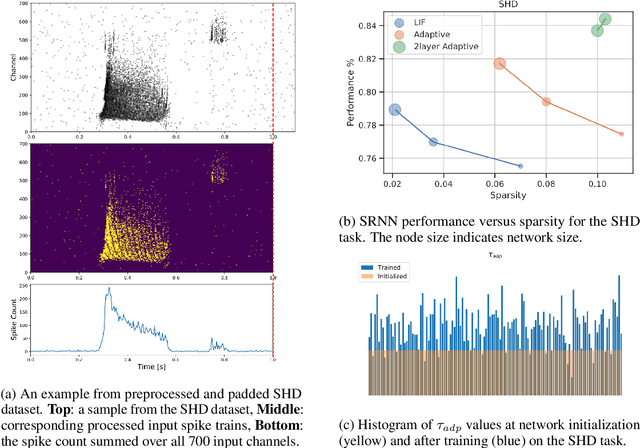
The emergence of brain-inspired neuromorphic computing as a paradigm for edge AI is motivating the search for high-performance and efficient spiking neural networks to run on this hardware. However, compared to classical neural networks in deep learning, current spiking neural networks lack competitive performance in compelling areas. Here, for sequential and streaming tasks, we demonstrate how a novel type of adaptive spiking recurrent neural network (SRNN) is able to achieve state-of-the-art performance compared to other spiking neural networks and almost reach or exceed the performance of classical recurrent neural networks (RNNs) while exhibiting sparse activity. From this, we calculate a $>$100x energy improvement for our SRNNs over classical RNNs on the harder tasks. To achieve this, we model standard and adaptive multiple-timescale spiking neurons as self-recurrent neural units, and leverage surrogate gradients and auto-differentiation in the PyTorch Deep Learning framework to efficiently implement backpropagation-through-time, including learning of the important spiking neuron parameters to adapt our spiking neurons to the tasks.