 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Image Modeling as a Framework for Self-Supervised Learning across Eye Movements
Apr 12, 2024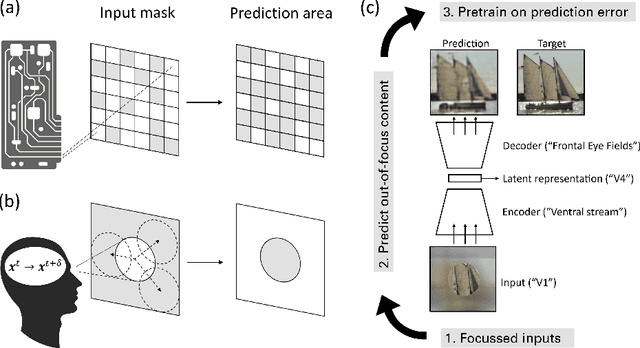


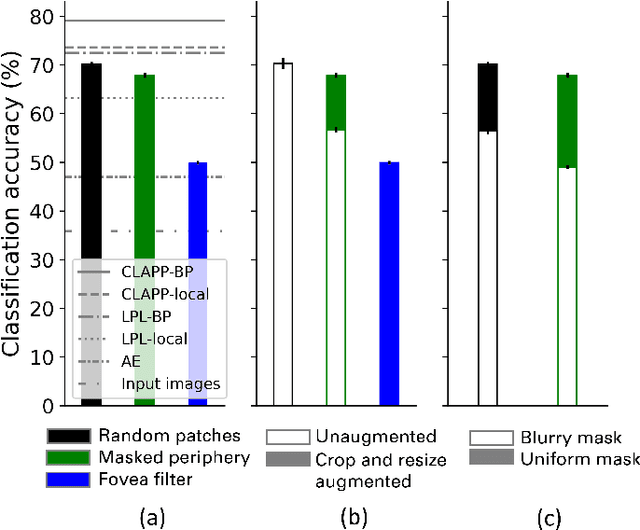
To make sense of their surroundings, intelligent systems must transform complex sensory inputs to structured codes that are reduced to task-relevant information such as object category. Biological agents achieve this in a largely autonomous manner, presumably via self-\allowbreak super-\allowbreak vised learning. Whereas previous attempts to model the underlying mechanisms were largely discriminative in nature, there is ample evidence that the brain employs a generative model of the world. Here, we propose that eye movements, in combination with the focused nature of primate vision, constitute a generative, self-supervised task of predicting and revealing visual information. We construct a proof-of-principle model starting from the framework of masked image modeling (MIM), a common approach in deep representation learning. To do so, we analyze how core components of MIM such as masking technique and data augmentation influence the formation of category-specific representations. This allows us not only to better understand the principles behind MIM, but to then reassemble a MIM more in line with the focused nature of biological perception. From a theoretical angle, we find that MIM disentangles neurons in latent space, a property that has been suggested to structure visual representations in primates, without explicit regulation. Together with previous findings of invariance learning, this highlights an interesting connection of MIM to latent regularization approaches for self-supervised learning. The source code is available under https://github.com/RobinWeiler/FocusMIM