 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine learning on DNA-encoded libraries: A new paradigm for hit-finding
Jan 31, 2020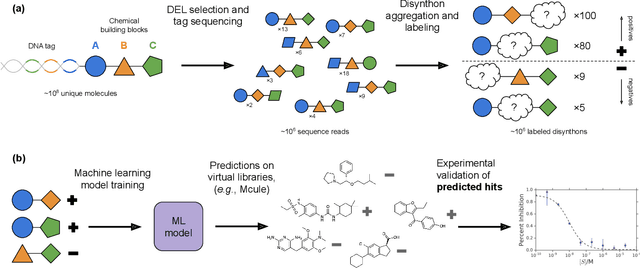
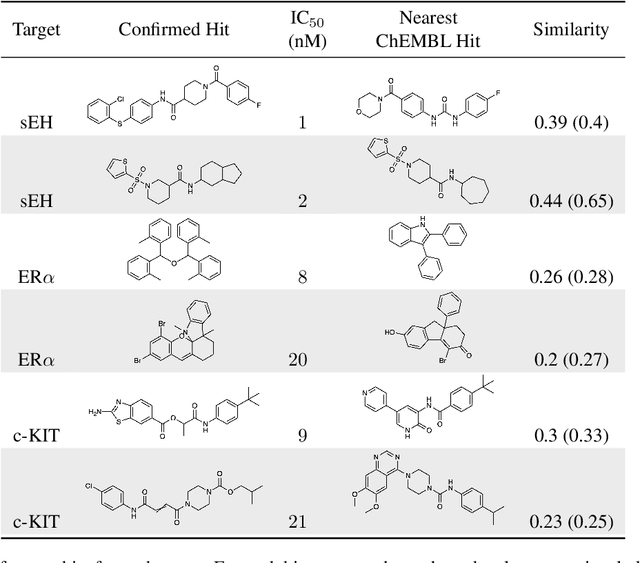
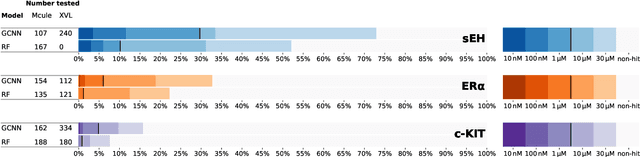
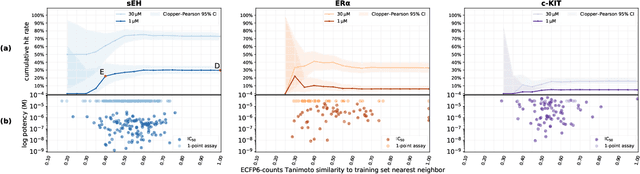
DNA-encoded small molecule libraries (DELs) have enabled discovery of novel inhibitors for many distinct protein targets of therapeutic value through screening of libraries with up to billions of unique small molecules. We demonstrate a new approach applying machine learning to DEL selection data by identifying active molecules from a large commercial collection and a virtual library of easily synthesizable compounds. We train models using only DEL selection data and apply automated or automatable filters with chemist review restricted to the removal of molecules with potential for instability or reactivity. We validate this approach with a large prospective study (nearly 2000 compounds tested) across three diverse protein targets: sEH (a hydrolase), ER{\alpha} (a nuclear receptor), and c-KIT (a kinase). The approach is effective, with an overall hit rate of {\sim}30% at 30 {\textmu}M and discovery of potent compounds (IC50 <10 nM) for every target. The model makes useful predictions even for molecules dissimilar to the original DEL and the compounds identified are diverse, predominantly drug-like, and different from known ligands. Collectively, the quality and quantity of DEL selection data; the power of modern machine learning methods; and access to large, inexpensive, commercially-available libraries creates a powerful new approach for hit finding.