 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSearching for actual causes: Approximate algorithms with adjustable precision
Jul 10, 2025Causality has gained popularity in recent years. It has helped improve the performance, reliability, and interpretability of machine learning models. However, recent literature on explainable artificial intelligence (XAI) has faced criticism. The classical XAI and causality literature focuses on understanding which factors contribute to which consequences. While such knowledge is valuable for researchers and engineers, it is not what non-expert users expect as explanations. Instead, these users often await facts that cause the target consequences, i.e., actual causes. Formalizing this notion is still an open problem. Additionally, identifying actual causes is reportedly an NP-complete problem, and there are too few practical solutions to approximate formal definitions. We propose a set of algorithms to identify actual causes with a polynomial complexity and an adjustable level of precision and exhaustiveness. Our experiments indicate that the algorithms (1) identify causes for different categories of systems that are not handled by existing approaches (i.e., non-boolean, black-box, and stochastic systems), (2) can be adjusted to gain more precision and exhaustiveness with more computation time.
A Comprehensive Evaluation of the Copy Mechanism for Natural Language to SPARQL Query Generation
May 01, 2023In recent years, the field of neural machine translation (NMT) for SPARQL query generation has witnessed a significant growth. Recently, the incorporation of the copy mechanism with traditional encoder-decoder architectures and the use of pre-trained encoder-decoders have set new performance benchmarks. This paper presents a large variety of experiments that replicate and expand upon recent NMT-based SPARQL generation studies, comparing pre-trained and non-pre-trained models, question annotation formats, and the use of a copy mechanism for non-pre-trained and pre-trained models. Our results show that either adding the copy mechanism or using a question annotation improves performances for nonpre-trained models and for pre-trained models, setting new baselines for three popular datasets.
A Copy Mechanism for Handling Knowledge Base Elements in SPARQL Neural Machine Translation
Nov 18, 2022
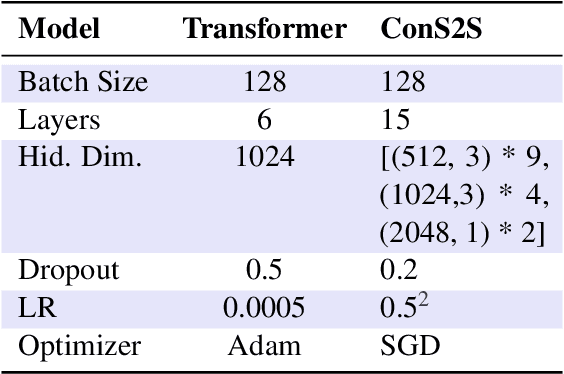
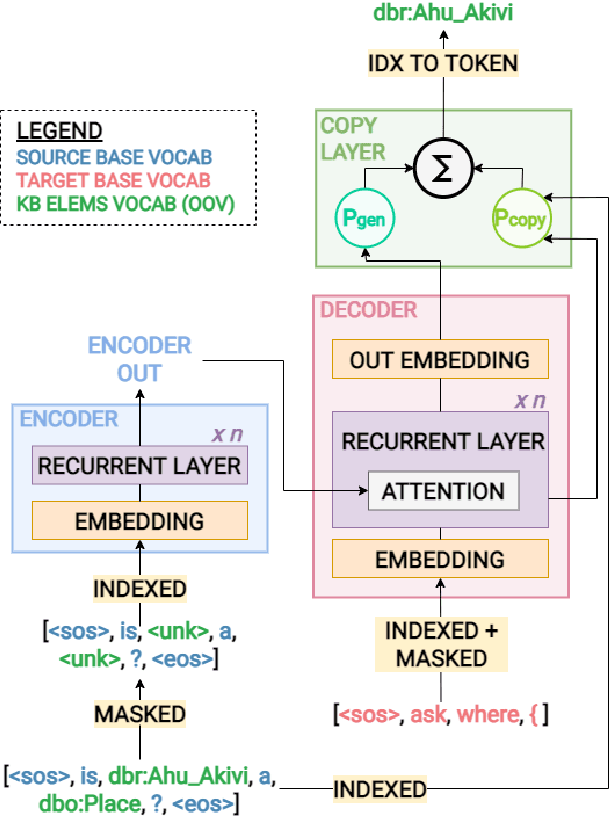
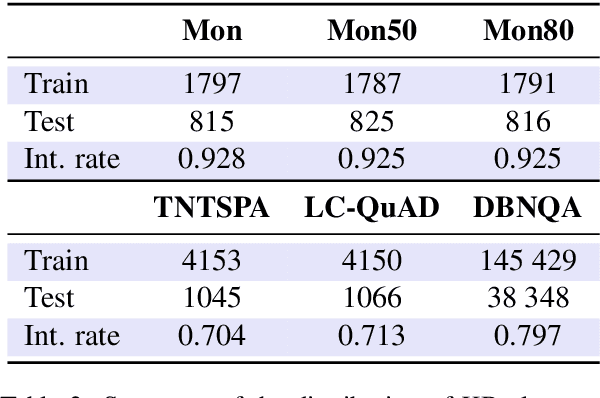
Neural Machine Translation (NMT) models from English to SPARQL are a promising development for SPARQL query generation. However, current architectures are unable to integrate the knowledge base (KB) schema and handle questions on knowledge resources, classes, and properties unseen during training, rendering them unusable outside the scope of topics covered in the training set. Inspired by the performance gains in natural language processing tasks, we propose to integrate a copy mechanism for neural SPARQL query generation as a way to tackle this issue. We illustrate our proposal by adding a copy layer and a dynamic knowledge base vocabulary to two Seq2Seq architectures (CNNs and Transformers). This layer makes the models copy KB elements directly from the questions, instead of generating them. We evaluate our approach on state-of-the-art datasets, including datasets referencing unknown KB elements and measure the accuracy of the copy-augmented architectures. Our results show a considerable increase in performance on all datasets compared to non-copy architectures.