 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruKAN: Towards More Efficient Kolmogorov-Arnold Networks Using Truncated Power Functions
Feb 02, 2026To address the trade-off between computational efficiency and adherence to Kolmogorov-Arnold Network (KAN) principles, we propose TruKAN, a new architecture based on the KAN structure and learnable activation functions. TruKAN replaces the B-spline basis in KAN with a family of truncated power functions derived from k-order spline theory. This change maintains the KAN's expressiveness while enhancing accuracy and training time. Each TruKAN layer combines a truncated power term with a polynomial term and employs either shared or individual knots. TruKAN exhibits greater interpretability than other KAN variants due to its simplified basis functions and knot configurations. By prioritizing interpretable basis functions, TruKAN aims to balance approximation efficacy with transparency. We develop the TruKAN model and integrate it into an advanced EfficientNet-V2-based framework, which is then evaluated on computer vision benchmark datasets. To ensure a fair comparison, we develop various models: MLP-, KAN-, SineKAN and TruKAN-based EfficientNet frameworks and assess their training time and accuracy across small and deep architectures. The training phase uses hybrid optimization to improve convergence stability. Additionally, we investigate layer normalization techniques for all the models and assess the impact of shared versus individual knots in TruKAN. Overall, TruKAN outperforms other KAN models in terms of accuracy, computational efficiency and memory usage on the complex vision task, demonstrating advantages beyond the limited settings explored in prior KAN studies.
Adaptive Learning for Service Monitoring Data
Aug 25, 2022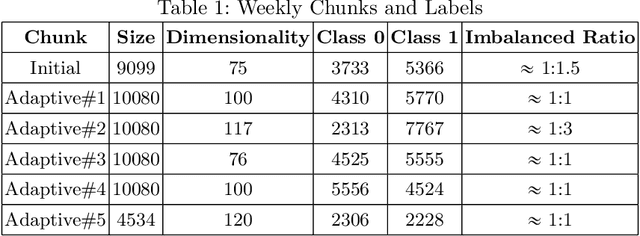
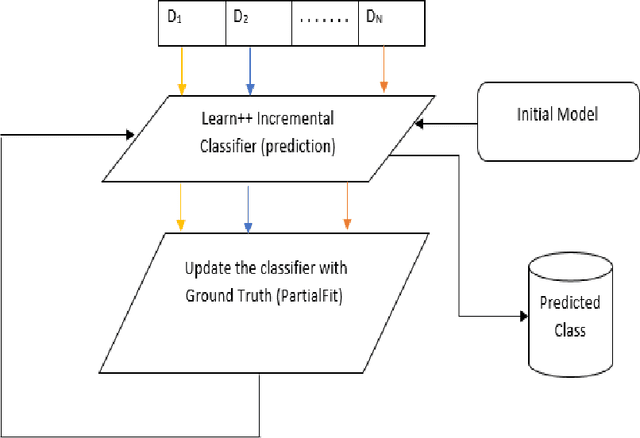
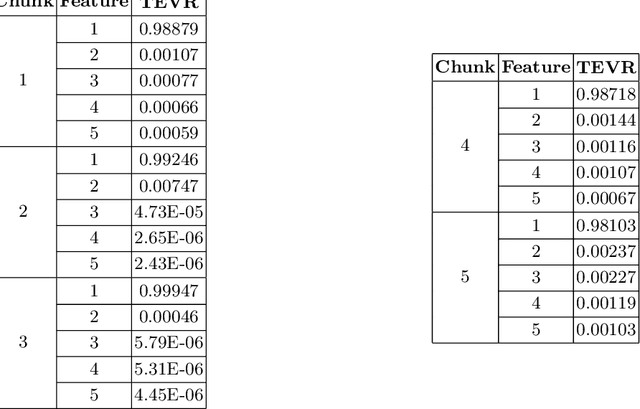
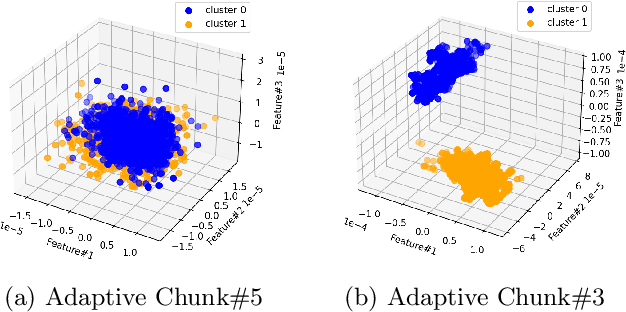
Service monitoring applications continuously produce data to monitor their availability. Hence, it is critical to classify incoming data in real-time and accurately. For this purpose, our study develops an adaptive classification approach using Learn++ that can handle evolving data distributions. This approach sequentially predicts and updates the monitoring model with new data, gradually forgets past knowledge and identifies sudden concept drift. We employ consecutive data chunks obtained from an industrial application to evaluate the performance of the predictors incrementally.
Incremental Feature Learning For Infinite Data
Aug 06, 2021



This study addresses the actual behavior of the credit-card fraud detection environment where financial transactions containing sensitive data must not be amassed in an enormous amount to conduct learning. We introduce a new adaptive learning approach that adjusts frequently and efficiently to new transaction chunks; each chunk is discarded after each incremental training step. Our approach combines transfer learning and incremental feature learning. The former improves the feature relevancy for subsequent chunks, and the latter, a new paradigm, increases accuracy during training by determining the optimal network architecture dynamically for each new chunk. The architectures of past incremental approaches are fixed; thus, the accuracy may not improve with new chunks. We show the effectiveness and superiority of our approach experimentally on an actual fraud dataset.
Optimizing Neural Network Weights using Nature-Inspired Algorithms
May 20, 2021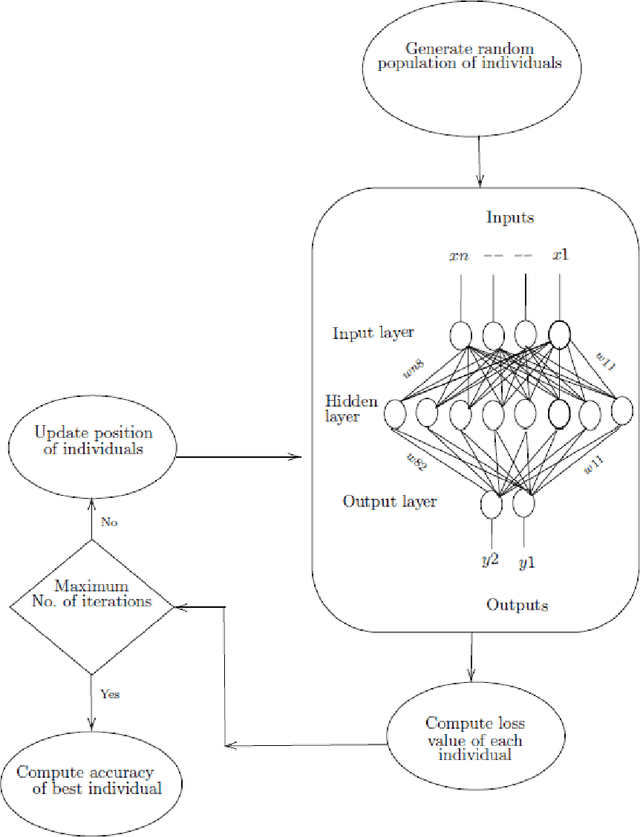
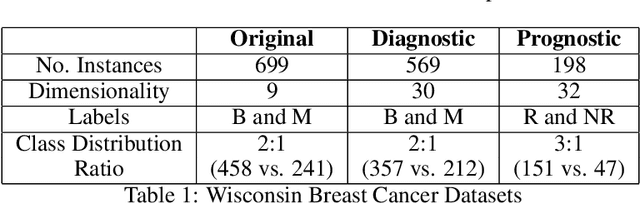
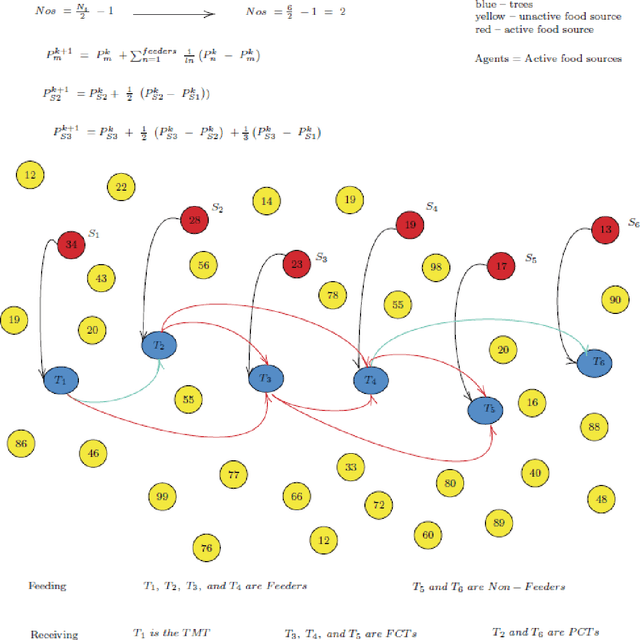
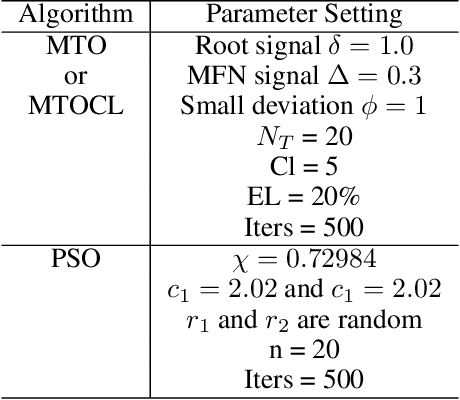
This study aims to optimize Deep Feedforward Neural Networks (DFNNs) training using nature-inspired optimization algorithms, such as PSO, MTO, and its variant called MTOCL. We show how these algorithms efficiently update the weights of DFNNs when learning from data. We evaluate the performance of DFNN fused with optimization algorithms using three Wisconsin breast cancer datasets, Original, Diagnostic, and Prognosis, under different experimental scenarios. The empirical analysis demonstrates that MTOCL is the most performing in most scenarios across the three datasets. Also, MTOCL is comparable to past weight optimization algorithms for the original dataset, and superior for the other datasets, especially for the challenging Prognostic dataset.
Cost-sensitive Semi-supervised Classification for Fraud Applications
Dec 21, 2020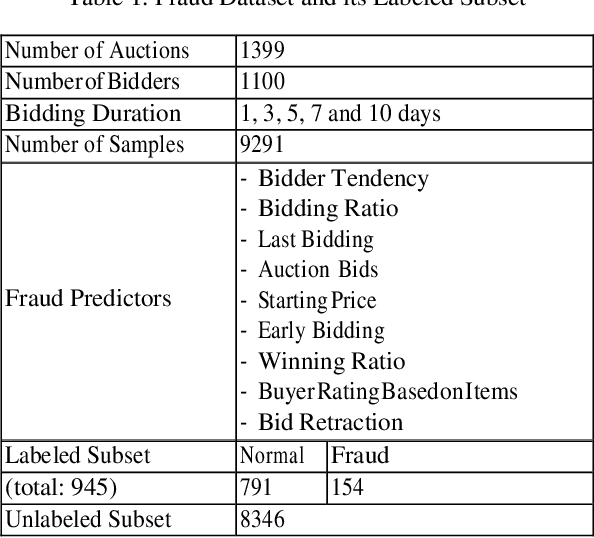
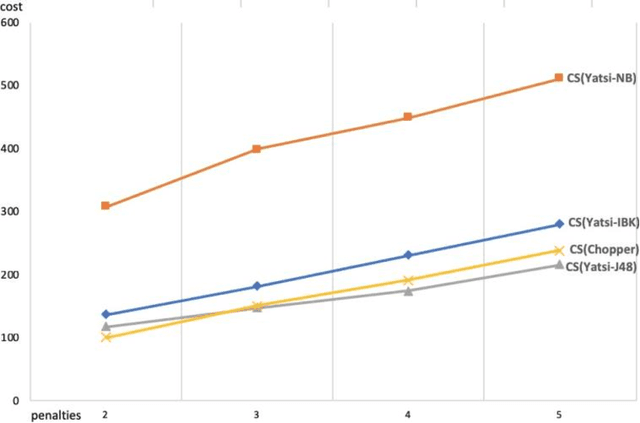

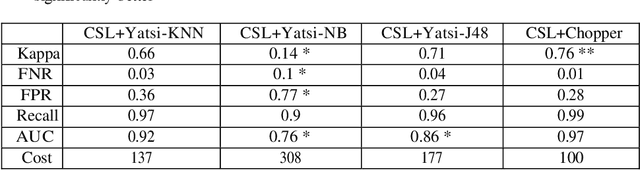
This research explores Cost-Sensitive Learning (CSL) in the fraud detection domain to decrease the fraud class's incorrect predictions and increase its accuracy. Notably, we concentrate on shill bidding fraud that is challenging to detect because the behavior of shill and legitimate bidders are similar. We investigate CSL within the Semi-Supervised Classification (SSC) framework to address the scarcity of labeled fraud data. Our paper is the first attempt to integrate CSL with SSC for fraud detection. We adopt a meta-CSL approach to manage the costs of misclassification errors, while SSC algorithms are trained with imbalanced data. Using an actual shill bidding dataset, we assess the performance of several hybrid models of CSL and SSC and then compare their misclassification error and accuracy rates statistically. The most efficient CSL+SSC model was able to detect 99% of fraudsters and with the lowest total cost.
Effect of Word Embedding Models on Hate and Offensive Speech Detection
Nov 23, 2020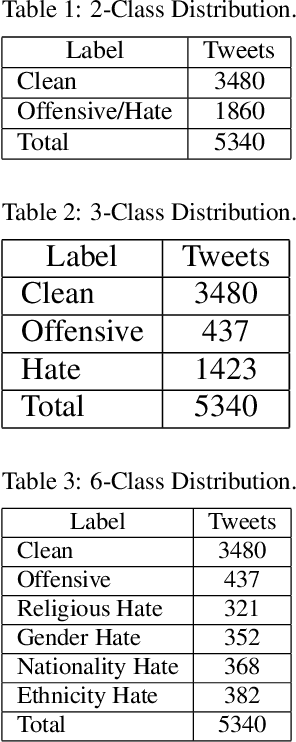
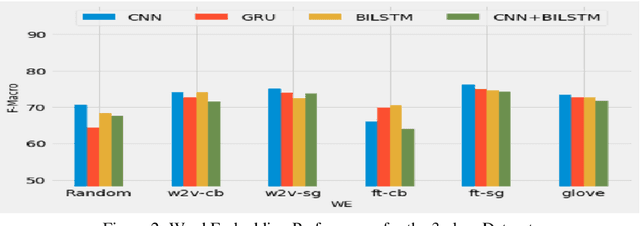
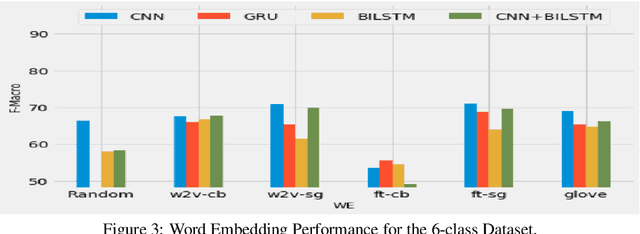
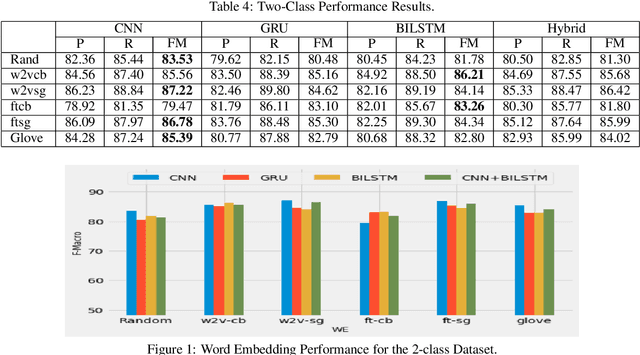
Deep neural networks have been adopted successfully in hate speech detection problems. Nevertheless, the effect of the word embedding models on the neural network's performance has not been appropriately examined in the literature. In our study, through different detection tasks, 2-class, 3-class, and 6-class classification, we investigate the impact of both word embedding models and neural network architectures on the predictive accuracy. Our focus is on the Arabic language. We first train several word embedding models on a large-scale unlabelled Arabic text corpus. Next, based on a dataset of Arabic hate and offensive speech, for each detection task, we train several neural network classifiers using the pre-trained word embedding models. This task yields a large number of various learned models, which allows conducting an exhaustive comparison. The empirical analysis demonstrates, on the one hand, the superiority of the skip-gram models and, on the other hand, the superiority of the CNN network across the three detection tasks.
Building High-Quality Auction Fraud Dataset
Jun 28, 2019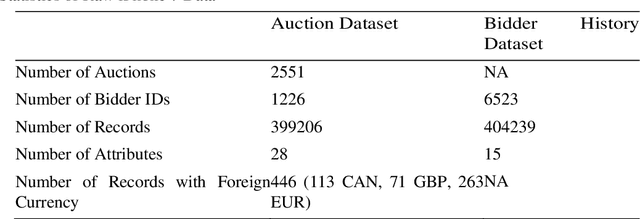
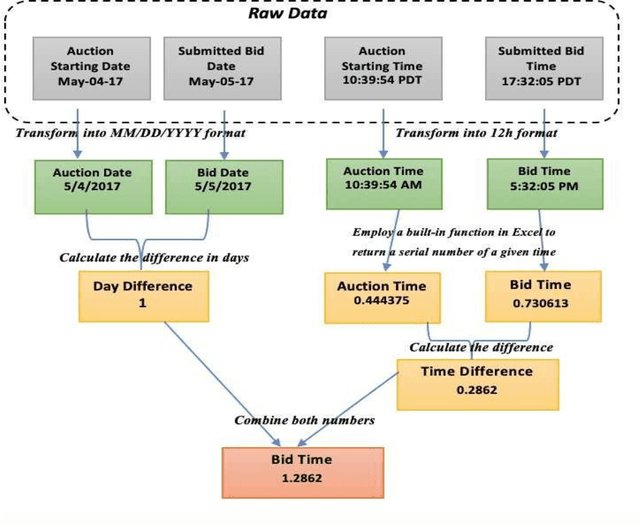
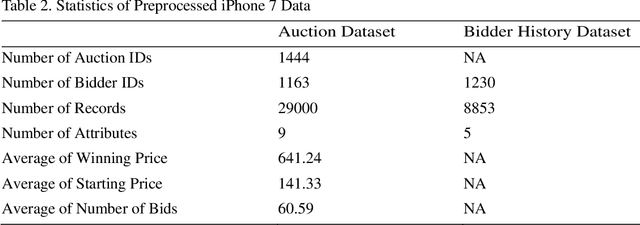

Given the magnitude of online auction transactions, it is difficult to safeguard consumers from dishonest sellers, such as shill bidders. To date, the application of machine learning to auction fraud detection has been limited. Shill Bidding (SB) is a severe auction fraud, which is driven by modern-day technologies and clever scammers. The difficulty of identifying the behavior of sophisticated fraudsters and the unavailability of training datasets hinder the research on SB detection. The aim of this study is to develop a high-quality SB dataset. To do so, first, we crawled and preprocessed a large number of commercial auctions and bidders' history as well. We thoroughly preprocessed both datasets to make them usable for the computation of the SB metrics. Nevertheless, this operation requires a deep understanding of the behavior of auctions and bidders. Second, we introduced two new SB patterns and implemented other existing ones. Finally, we removed outliers to improve the quality of the training fraud data.
Clustering and Labelling Auction Fraud Data
Aug 22, 2018

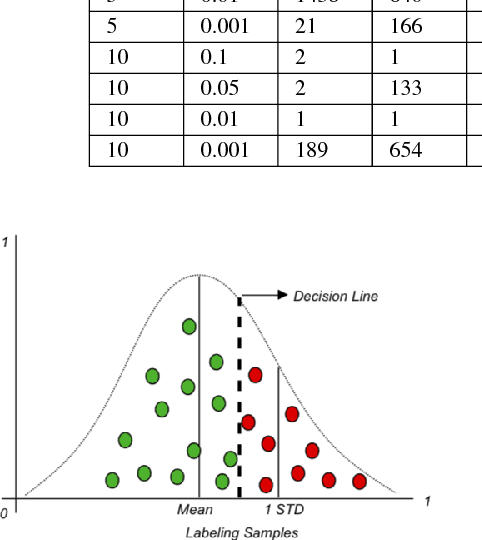

Although shill bidding is a common auction fraud, it is however very tough to detect. Due to the unavailability and lack of training data, in this study, we build a high-quality labeled shill bidding dataset based on recently collected auctions from eBay. Labeling shill biding instances with multidimensional features is a critical phase for the fraud classification task. For this purpose, we introduce a new approach to systematically label the fraud data with the help of the hierarchical clustering CURE that returns remarkable results as illustrated in the experiments.
Scraping and Preprocessing Commercial Auction Data for Fraud Classification
Jun 17, 2018


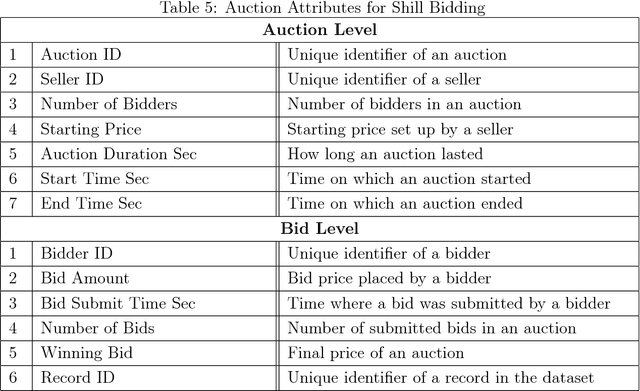
In the last three decades, we have seen a significant increase in trading goods and services through online auctions. However, this business created an attractive environment for malicious moneymakers who can commit different types of fraud activities, such as Shill Bidding (SB). The latter is predominant across many auctions but this type of fraud is difficult to detect due to its similarity to normal bidding behaviour. The unavailability of SB datasets makes the development of SB detection and classification models burdensome. Furthermore, to implement efficient SB detection models, we should produce SB data from actual auctions of commercial sites. In this study, we first scraped a large number of eBay auctions of a popular product. After preprocessing the raw auction data, we build a high-quality SB dataset based on the most reliable SB strategies. The aim of our research is to share the preprocessed auction dataset as well as the SB training (unlabelled) dataset, thereby researchers can apply various machine learning techniques by using authentic data of auctions and fraud.