 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering and Labelling Auction Fraud Data
Aug 22, 2018

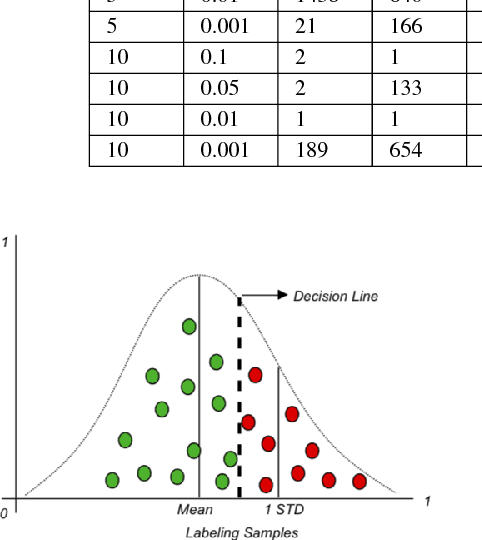

Although shill bidding is a common auction fraud, it is however very tough to detect. Due to the unavailability and lack of training data, in this study, we build a high-quality labeled shill bidding dataset based on recently collected auctions from eBay. Labeling shill biding instances with multidimensional features is a critical phase for the fraud classification task. For this purpose, we introduce a new approach to systematically label the fraud data with the help of the hierarchical clustering CURE that returns remarkable results as illustrated in the experiments.
Scraping and Preprocessing Commercial Auction Data for Fraud Classification
Jun 17, 2018


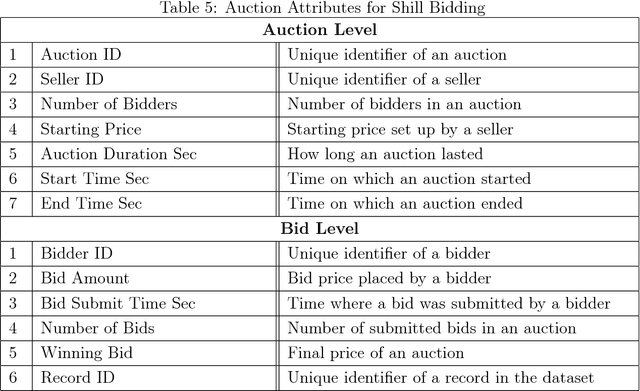
In the last three decades, we have seen a significant increase in trading goods and services through online auctions. However, this business created an attractive environment for malicious moneymakers who can commit different types of fraud activities, such as Shill Bidding (SB). The latter is predominant across many auctions but this type of fraud is difficult to detect due to its similarity to normal bidding behaviour. The unavailability of SB datasets makes the development of SB detection and classification models burdensome. Furthermore, to implement efficient SB detection models, we should produce SB data from actual auctions of commercial sites. In this study, we first scraped a large number of eBay auctions of a popular product. After preprocessing the raw auction data, we build a high-quality SB dataset based on the most reliable SB strategies. The aim of our research is to share the preprocessed auction dataset as well as the SB training (unlabelled) dataset, thereby researchers can apply various machine learning techniques by using authentic data of auctions and fraud.