 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffect of Word Embedding Models on Hate and Offensive Speech Detection
Paper and Code
Nov 23, 2020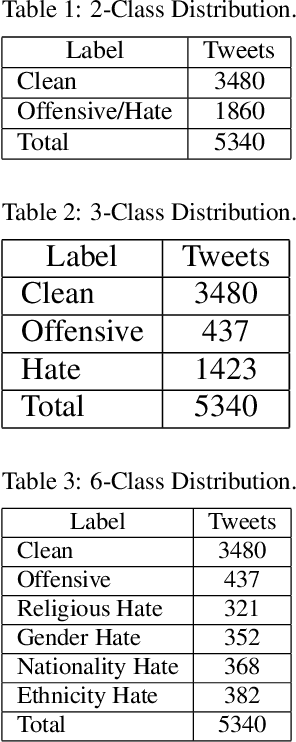
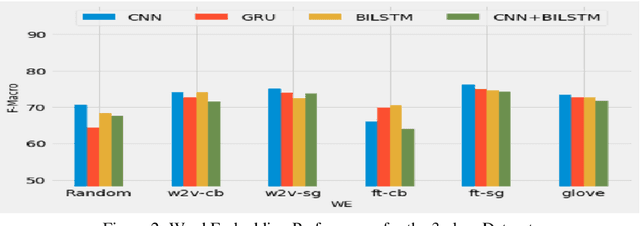
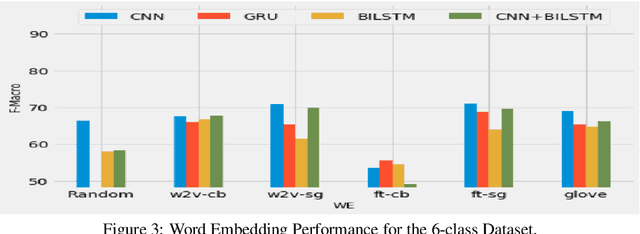
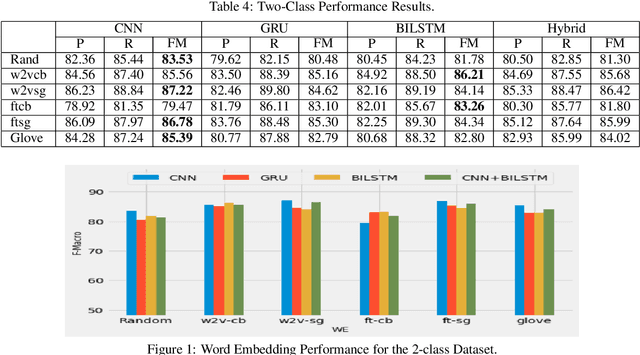
Deep neural networks have been adopted successfully in hate speech detection problems. Nevertheless, the effect of the word embedding models on the neural network's performance has not been appropriately examined in the literature. In our study, through different detection tasks, 2-class, 3-class, and 6-class classification, we investigate the impact of both word embedding models and neural network architectures on the predictive accuracy. Our focus is on the Arabic language. We first train several word embedding models on a large-scale unlabelled Arabic text corpus. Next, based on a dataset of Arabic hate and offensive speech, for each detection task, we train several neural network classifiers using the pre-trained word embedding models. This task yields a large number of various learned models, which allows conducting an exhaustive comparison. The empirical analysis demonstrates, on the one hand, the superiority of the skip-gram models and, on the other hand, the superiority of the CNN network across the three detection tasks.