 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConfidential Machine Learning within Graphcore IPUs
May 20, 2022
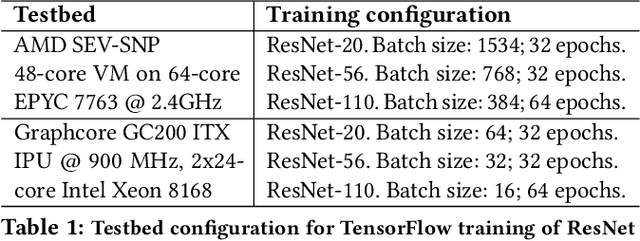
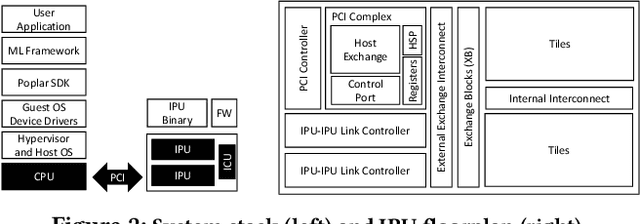
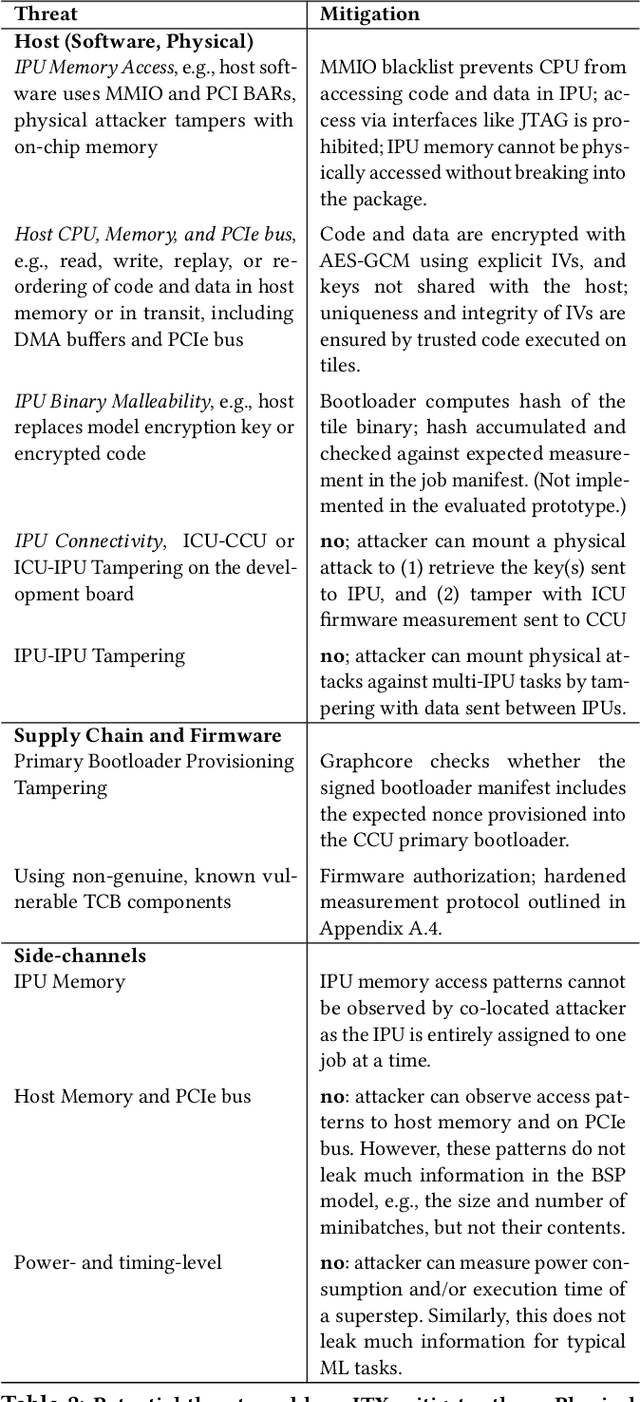
We present IPU Trusted Extensions (ITX), a set of experimental hardware extensions that enable trusted execution environments in Graphcore's AI accelerators. ITX enables the execution of AI workloads with strong confidentiality and integrity guarantees at low performance overheads. ITX isolates workloads from untrusted hosts, and ensures their data and models remain encrypted at all times except within the IPU. ITX includes a hardware root-of-trust that provides attestation capabilities and orchestrates trusted execution, and on-chip programmable cryptographic engines for authenticated encryption of code and data at PCIe bandwidth. We also present software for ITX in the form of compiler and runtime extensions that support multi-party training without requiring a CPU-based TEE. Experimental support for ITX is included in Graphcore's GC200 IPU taped out at TSMC's 7nm technology node. Its evaluation on a development board using standard DNN training workloads suggests that ITX adds less than 5% performance overhead, and delivers up to 17x better performance compared to CPU-based confidential computing systems relying on AMD SEV-SNP.
AMPNet: Asynchronous Model-Parallel Training for Dynamic Neural Networks
Jun 22, 2017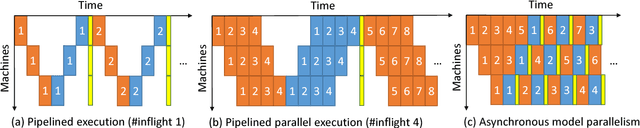
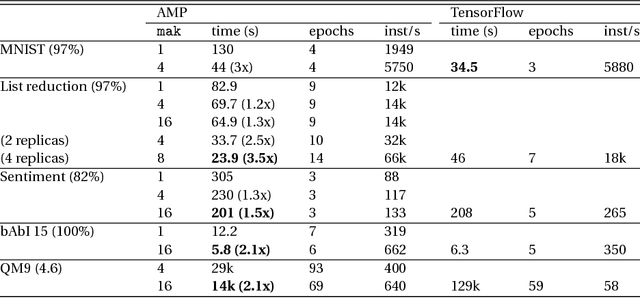
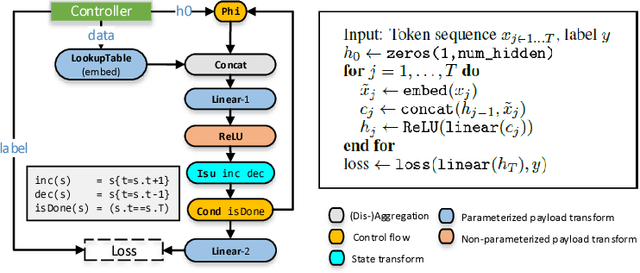
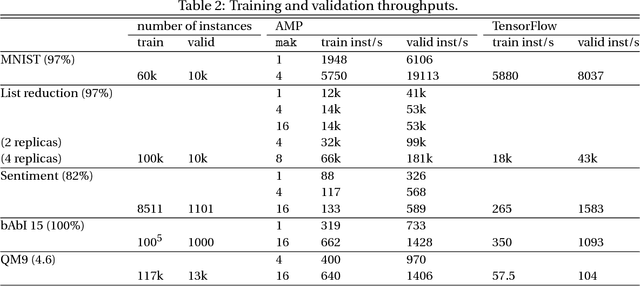
New types of machine learning hardware in development and entering the market hold the promise of revolutionizing deep learning in a manner as profound as GPUs. However, existing software frameworks and training algorithms for deep learning have yet to evolve to fully leverage the capability of the new wave of silicon. We already see the limitations of existing algorithms for models that exploit structured input via complex and instance-dependent control flow, which prohibits minibatching. We present an asynchronous model-parallel (AMP) training algorithm that is specifically motivated by training on networks of interconnected devices. Through an implementation on multi-core CPUs, we show that AMP training converges to the same accuracy as conventional synchronous training algorithms in a similar number of epochs, but utilizes the available hardware more efficiently even for small minibatch sizes, resulting in significantly shorter overall training times. Our framework opens the door for scaling up a new class of deep learning models that cannot be efficiently trained today.