 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAMPNet: Asynchronous Model-Parallel Training for Dynamic Neural Networks
Jun 22, 2017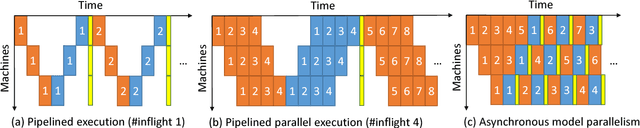
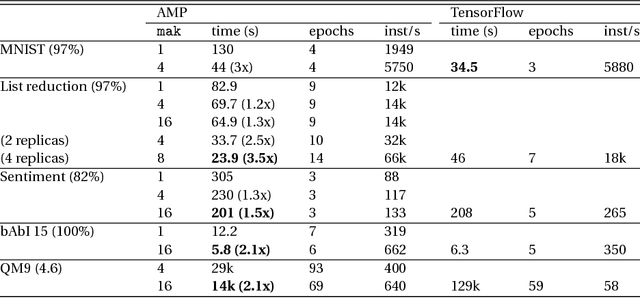
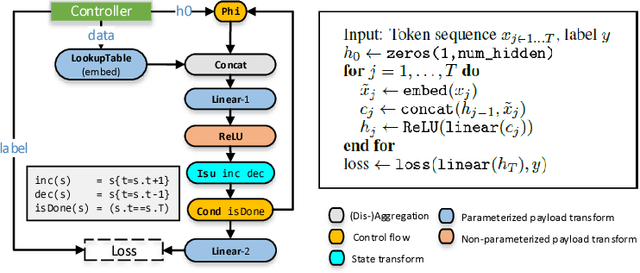
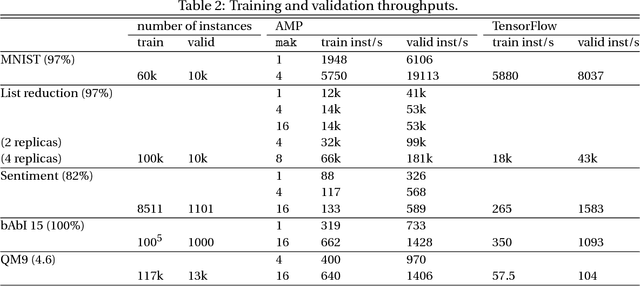
New types of machine learning hardware in development and entering the market hold the promise of revolutionizing deep learning in a manner as profound as GPUs. However, existing software frameworks and training algorithms for deep learning have yet to evolve to fully leverage the capability of the new wave of silicon. We already see the limitations of existing algorithms for models that exploit structured input via complex and instance-dependent control flow, which prohibits minibatching. We present an asynchronous model-parallel (AMP) training algorithm that is specifically motivated by training on networks of interconnected devices. Through an implementation on multi-core CPUs, we show that AMP training converges to the same accuracy as conventional synchronous training algorithms in a similar number of epochs, but utilizes the available hardware more efficiently even for small minibatch sizes, resulting in significantly shorter overall training times. Our framework opens the door for scaling up a new class of deep learning models that cannot be efficiently trained today.