 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Transformed Learning for a Circular, Secure, and Tiny AI
Nov 24, 2023Deep Learning (DL) is penetrating into a diverse range of mass mobility, smart living, and industrial applications, rapidly transforming the way we live and work. DL is at the heart of many AI implementations. A key set of challenges is to produce AI modules that are: (1) "circular" - can solve new tasks without forgetting how to solve previous ones, (2) "secure" - have immunity to adversarial data attacks, and (3) "tiny" - implementable in low power low cost embedded hardware. Clearly it is difficult to achieve all three aspects on a single horizontal layer of platforms, as the techniques require transformed deep representations that incur different computation and communication requirements. Here we set out the vision to achieve transformed DL representations across a 5G and Beyond networked architecture. We first detail the cross-sectoral motivations for each challenge area, before demonstrating recent advances in DL research that can achieve circular, secure, and tiny AI (CST-AI). Recognising the conflicting demand of each transformed deep representation, we federate their deep learning transformations and functionalities across the network to achieve connected run-time capabilities.
Generating Explanations from Deep Reinforcement Learning Using Episodic Memory
May 18, 2022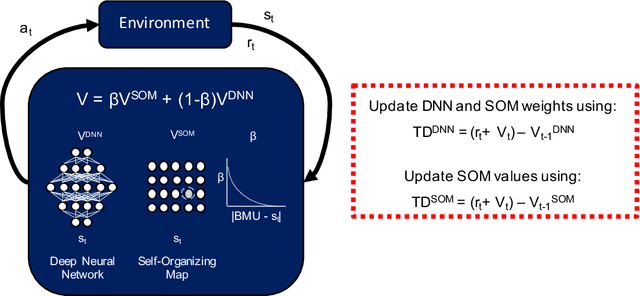
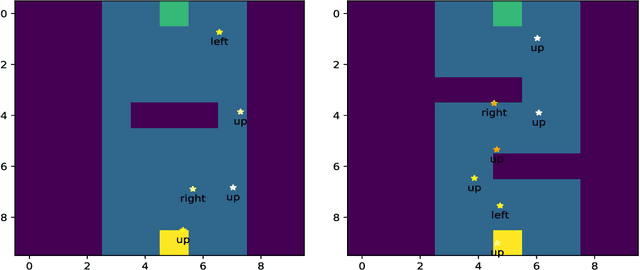
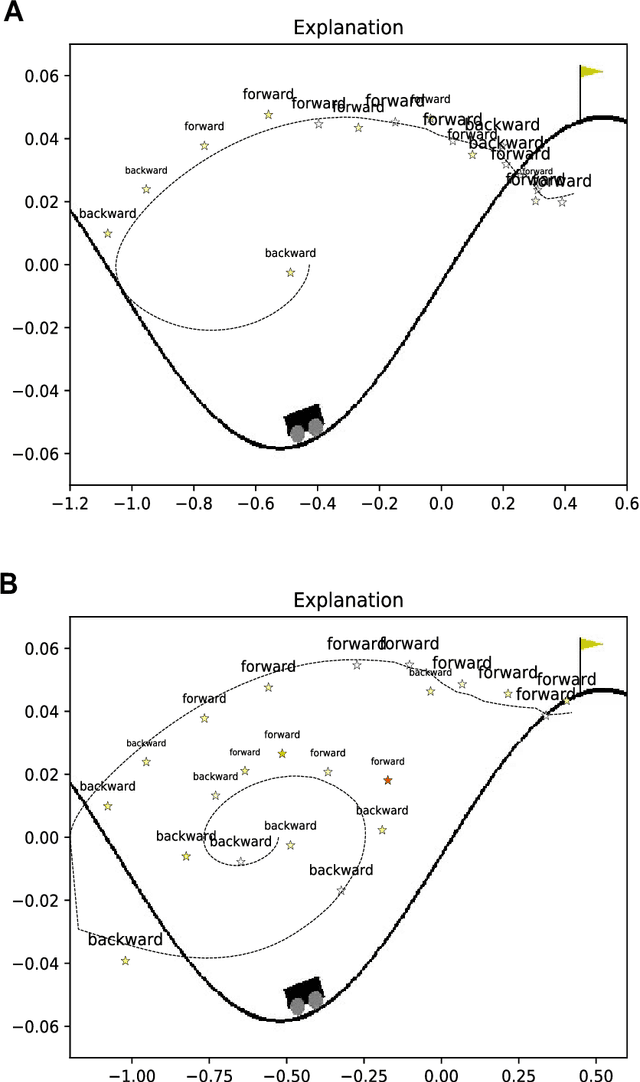
Deep Reinforcement Learning (RL) involves the use of Deep Neural Networks (DNNs) to make sequential decisions in order to maximize reward. For many tasks the resulting sequence of actions produced by a Deep RL policy can be long and difficult to understand for humans. A crucial component of human explanations is selectivity, whereby only key decisions and causes are recounted. Imbuing Deep RL agents with such an ability would make their resulting policies easier to understand from a human perspective and generate a concise set of instructions to aid the learning of future agents. To this end we use a Deep RL agent with an episodic memory system to identify and recount key decisions during policy execution. We show that these decisions form a short, human readable explanation that can also be used to speed up the learning of naive Deep RL agents in an algorithm-independent manner.
Selective Particle Attention: Visual Feature-Based Attention in Deep Reinforcement Learning
Aug 26, 2020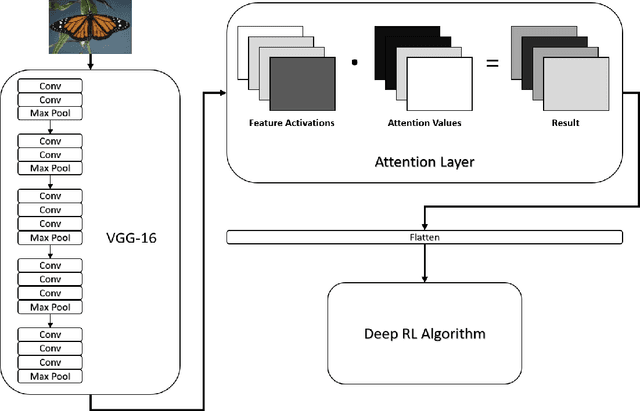
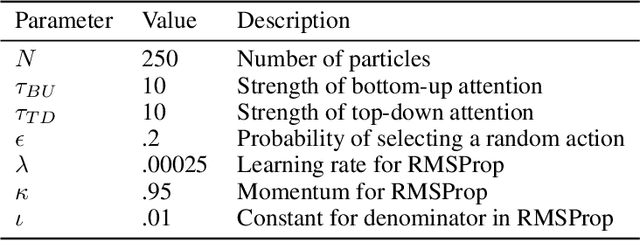

The human brain uses selective attention to filter perceptual input so that only the components that are useful for behaviour are processed using its limited computational resources. We focus on one particular form of visual attention known as feature-based attention, which is concerned with identifying features of the visual input that are important for the current task regardless of their spatial location. Visual feature-based attention has been proposed to improve the efficiency of Reinforcement Learning (RL) by reducing the dimensionality of state representations and guiding learning towards relevant features. Despite achieving human level performance in complex perceptual-motor tasks, Deep RL algorithms have been consistently criticised for their poor efficiency and lack of flexibility. Visual feature-based attention therefore represents one option for addressing these criticisms. Nevertheless, it is still an open question how the brain is able to learn which features to attend to during RL. To help answer this question we propose a novel algorithm, termed Selective Particle Attention (SPA), which imbues a Deep RL agent with the ability to perform selective feature-based attention. SPA learns which combinations of features to attend to based on their bottom-up saliency and how accurately they predict future reward. We evaluate SPA on a multiple choice task and a 2D video game that both involve raw pixel input and dynamic changes to the task structure. We show various benefits of SPA over approaches that naively attend to either all or random subsets of features. Our results demonstrate (1) how visual feature-based attention in Deep RL models can improve their learning efficiency and ability to deal with sudden changes in task structure and (2) that particle filters may represent a viable computational account of how visual feature-based attention occurs in the brain.
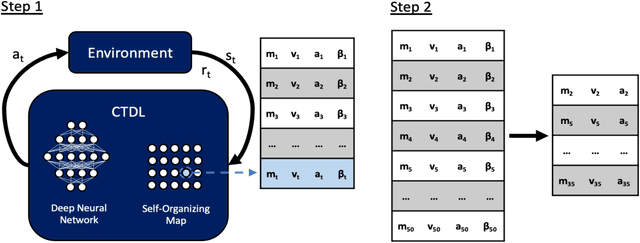
A Complementary Learning Systems Approach to Temporal Difference Learning
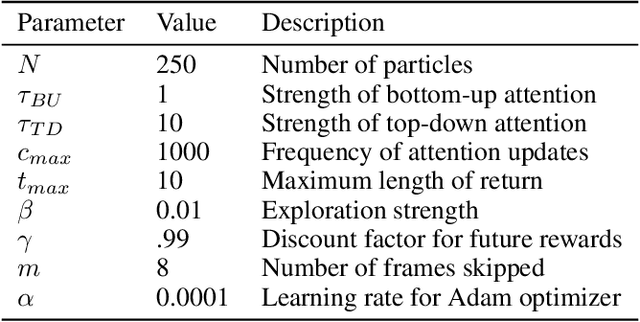
May 07, 2019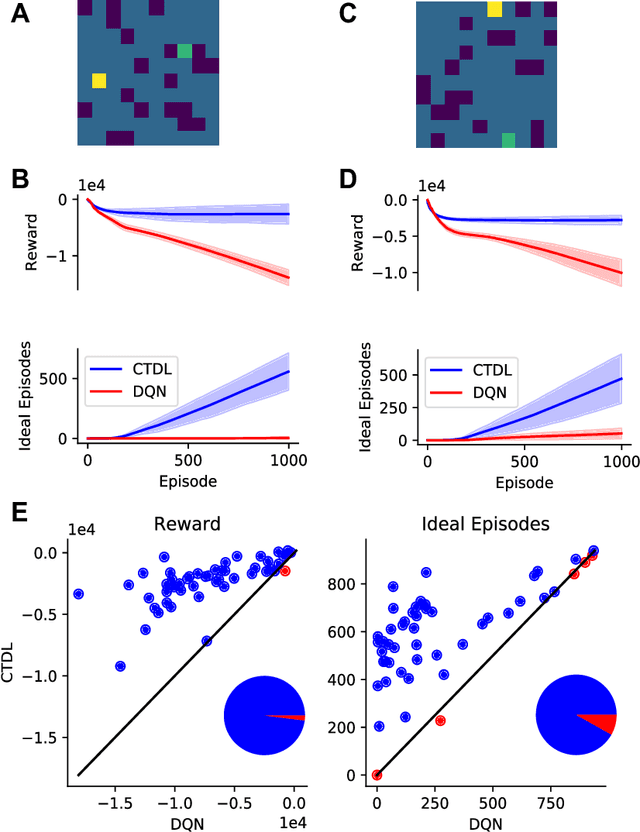

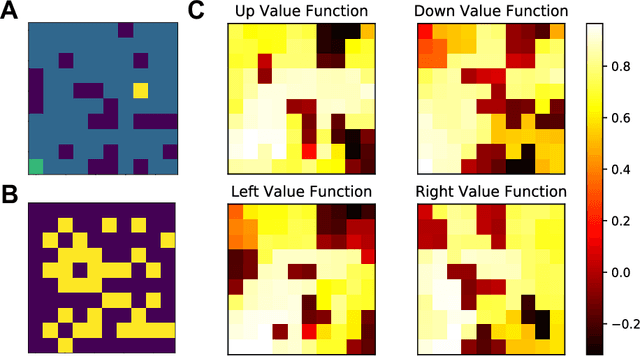
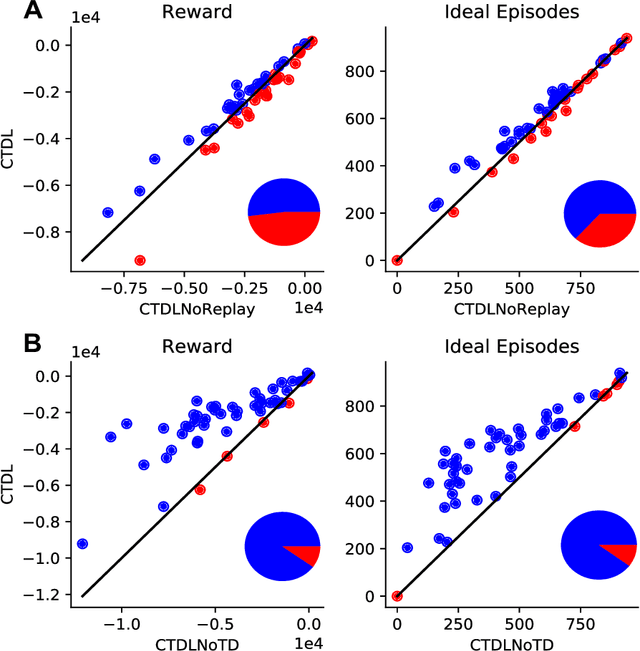
Complementary Learning Systems (CLS) theory suggests that the brain uses a 'neocortical' and a 'hippocampal' learning system to achieve complex behavior. These two systems are complementary in that the 'neocortical' system relies on slow learning of distributed representations while the 'hippocampal' system relies on fast learning of pattern-separated representations. Both of these systems project to the striatum, which is a key neural structure in the brain's implementation of Reinforcement Learning (RL). Current deep RL approaches share similarities with a 'neocortical' system because they slowly learn distributed representations through backpropagation in Deep Neural Networks (DNNs). An ongoing criticism of such approaches is that they are data inefficient and lack flexibility. CLS theory suggests that the addition of a 'hippocampal' system could address these criticisms. In the present study we propose a novel algorithm known as Complementary Temporal Difference Learning (CTDL), which combines a DNN with a Self-Organising Map (SOM) to obtain the benefits of both a 'neocortical' and a 'hippocampal' system. Key features of CTDL include the use of Temporal Difference (TD) error to update a SOM and the combination of a SOM and DNN to calculate action values. We evaluate CTDL on grid worlds and the Cart-Pole environment, and show several benefits over the classic Deep Q-Network (DQN) approach. These results demonstrate (1) the utility of complementary learning systems for the evaluation of actions, (2) that the TD error signal is a useful form of communication between the two systems and (3) the biological plausibility of the proposed approach.