 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Complementary Learning Systems Approach to Temporal Difference Learning
Paper and Code
May 07, 2019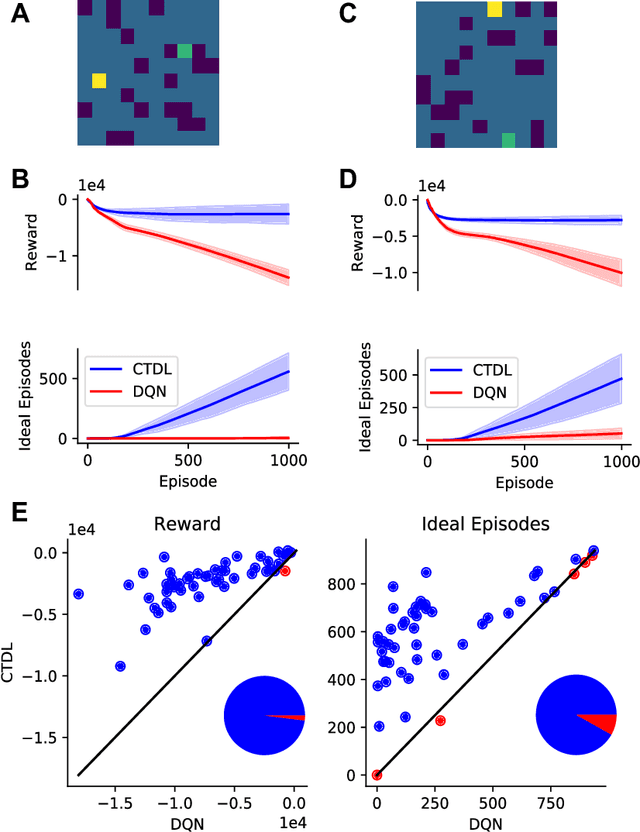

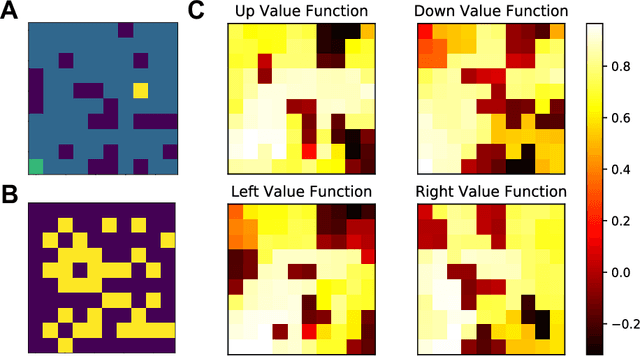
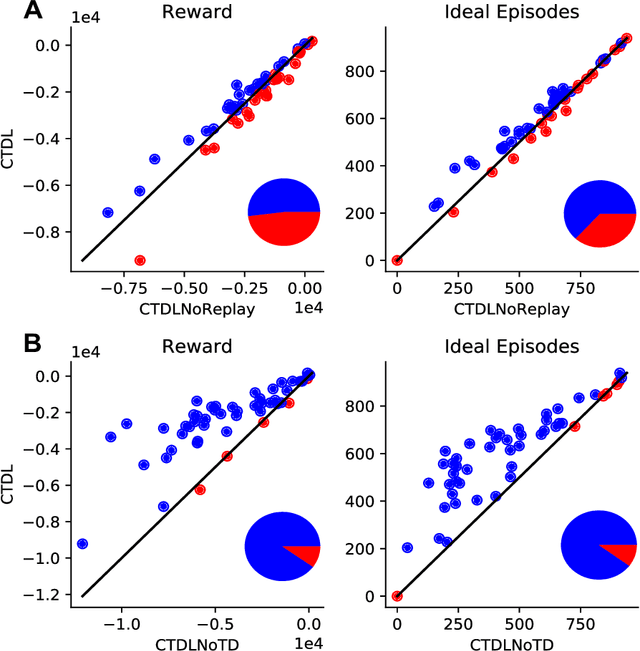
Complementary Learning Systems (CLS) theory suggests that the brain uses a 'neocortical' and a 'hippocampal' learning system to achieve complex behavior. These two systems are complementary in that the 'neocortical' system relies on slow learning of distributed representations while the 'hippocampal' system relies on fast learning of pattern-separated representations. Both of these systems project to the striatum, which is a key neural structure in the brain's implementation of Reinforcement Learning (RL). Current deep RL approaches share similarities with a 'neocortical' system because they slowly learn distributed representations through backpropagation in Deep Neural Networks (DNNs). An ongoing criticism of such approaches is that they are data inefficient and lack flexibility. CLS theory suggests that the addition of a 'hippocampal' system could address these criticisms. In the present study we propose a novel algorithm known as Complementary Temporal Difference Learning (CTDL), which combines a DNN with a Self-Organising Map (SOM) to obtain the benefits of both a 'neocortical' and a 'hippocampal' system. Key features of CTDL include the use of Temporal Difference (TD) error to update a SOM and the combination of a SOM and DNN to calculate action values. We evaluate CTDL on grid worlds and the Cart-Pole environment, and show several benefits over the classic Deep Q-Network (DQN) approach. These results demonstrate (1) the utility of complementary learning systems for the evaluation of actions, (2) that the TD error signal is a useful form of communication between the two systems and (3) the biological plausibility of the proposed approach.