 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLidar Annotation Is All You Need
Nov 08, 2023In recent years, computer vision has transformed fields such as medical imaging, object recognition, and geospatial analytics. One of the fundamental tasks in computer vision is semantic image segmentation, which is vital for precise object delineation. Autonomous driving represents one of the key areas where computer vision algorithms are applied. The task of road surface segmentation is crucial in self-driving systems, but it requires a labor-intensive annotation process in several data domains. The work described in this paper aims to improve the efficiency of image segmentation using a convolutional neural network in a multi-sensor setup. This approach leverages lidar (Light Detection and Ranging) annotations to directly train image segmentation models on RGB images. Lidar supplements the images by emitting laser pulses and measuring reflections to provide depth information. However, lidar's sparse point clouds often create difficulties for accurate object segmentation. Segmentation of point clouds requires time-consuming preliminary data preparation and a large amount of computational resources. The key innovation of our approach is the masked loss, addressing sparse ground-truth masks from point clouds. By calculating loss exclusively where lidar points exist, the model learns road segmentation on images by using lidar points as ground truth. This approach allows for blending of different ground-truth data types during model training. Experimental validation of the approach on benchmark datasets shows comparable performance to a high-quality image segmentation model. Incorporating lidar reduces the load on annotations and enables training of image-segmentation models without loss of segmentation quality. The methodology is tested on diverse datasets, both publicly available and proprietary. The strengths and weaknesses of the proposed method are also discussed in the paper.
CNN-based Omnidirectional Object Detection for HermesBot Autonomous Delivery Robot with Preliminary Frame Classification
Oct 22, 2021
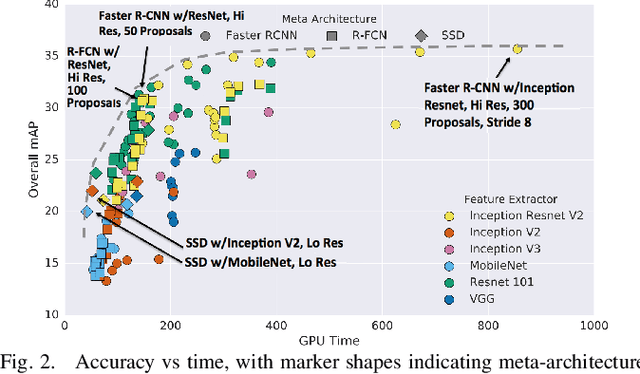
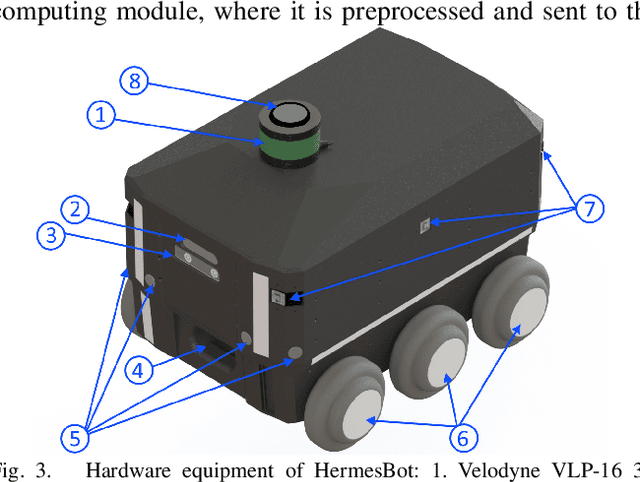
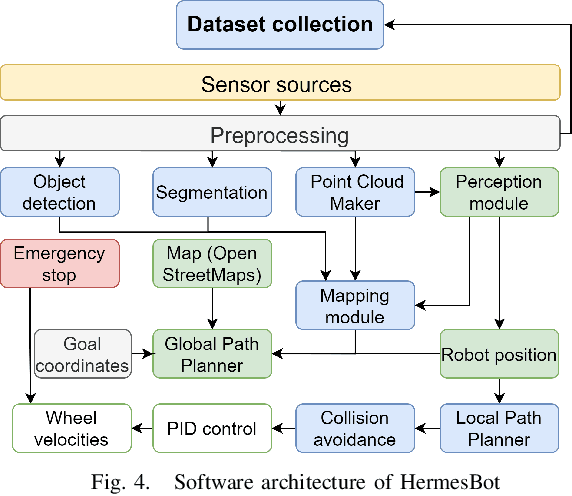
Mobile autonomous robots include numerous sensors for environment perception. Cameras are an essential tool for robot's localization, navigation, and obstacle avoidance. To process a large flow of data from the sensors, it is necessary to optimize algorithms, or to utilize substantial computational power. In our work, we propose an algorithm for optimizing a neural network for object detection using preliminary binary frame classification. An autonomous outdoor mobile robot with 6 rolling-shutter cameras on the perimeter providing a 360-degree field of view was used as the experimental setup. The obtained experimental results revealed that the proposed optimization accelerates the inference time of the neural network in the cases with up to 5 out of 6 cameras containing target objects.